Marketplace łańcucha dostaw oparty na AI
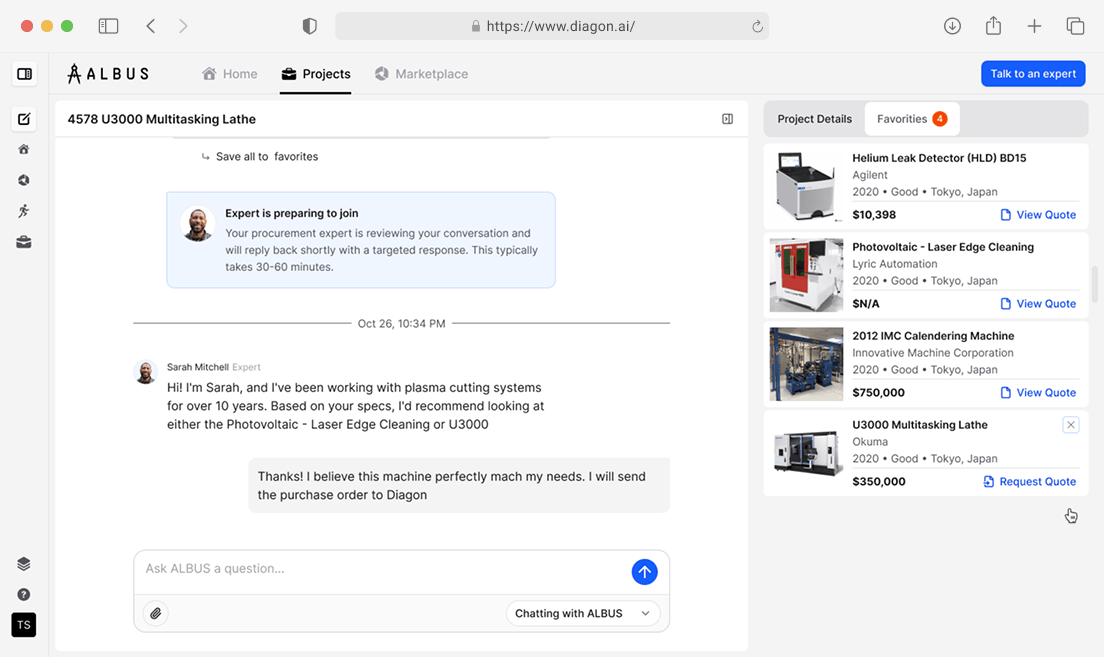
Budowa skalowalnego, autonomicznego silnika danych indeksującego ponad 32 000 dostawców dla startupu na etapie Series Seed, z wykorzystaniem agentów AI

Twoje dane siedzą w ERP, CRM, Excelach i kilku systemach SaaS. Scalamy je w jeden spójny fundament, na którym stawiasz rzetelne raporty i rozwiązania AI.
Łączymy ERP, CRM, e-commerce, Excele i aplikacje SaaS w jeden spójny obraz firmy. Koniec z ręcznym sklejaniem raportów z eksportów.
Projektujemy i wdrażamy hurtownie chmurowe oraz pipeline'y, które codziennie dostarczają świeże, zweryfikowane dane.
Przygotowujemy dane pod RAG, agentów AI i modele predykcyjne. Wdrażamy je razem z naszym zespołem AI, bez przekazywania projektu między firmami.
Samoobsługowa analityka dla zespołów biznesowych. Decyzje zapadają na danych z dziś, nie na eksportach sprzed tygodnia.
Pomagamy zrozumieć, co w Twoich danych już działa, co trzeba uporządkować i od czego zacząć, żeby raporty i AI mogły na nich polegać.




Najpierw rozumiemy, jak działa Twoja firma i jakie decyzje chcesz podejmować na danych. Dopiero potem dobieramy narzędzia.
Jeden zespół prowadzi Cię przez cały łańcuch: zbieranie danych, integrację, hurtownię, raporty i wdrożenia AI na gotowym fundamencie.
Pracujemy zgodnie z ISO 27001. Pomagamy spełnić wymagania RODO i uporządkować dostęp do danych w całej organizacji.
Pracujemy etapami: pierwsze zintegrowane raporty zobaczysz w tygodnie, nie po roku. Każdy etap kończy się działającym efektem.
Dzięki ISO 27001 i innym certyfikatom nasze usługi programistyczne są bezpieczne, niezawodne i zgodne z najwyższymi standardami branżowymi.





Od analizy, przez realizację, po utrzymanie — zapewniamy inżynierów z wymaganymi kompetencjami.
Nasze procesy QA spełniają najwyższe standardy dostarczania oprogramowania.
Twoje dane są bezpieczne, dbamy o nie zgodnie z ISO 27001 i najlepszymi praktykami w branży.
Pomagamy naszym klientom tworzyć rozwiązania, które dają przewagę technologiczną. Od pierwszego dnia projektu dostarczamy realne wyniki i realizujemy cele biznesowe, a nie tylko techniczne.








Budowa skalowalnego, autonomicznego silnika danych indeksującego ponad 32 000 dostawców dla startupu na etapie Series Seed, z wykorzystaniem agentów AI
Budowa produktu SaaS wykorzystującego AI/ML do analizy procesów zakupowych pod kątem wpływu na emisje Scope 3
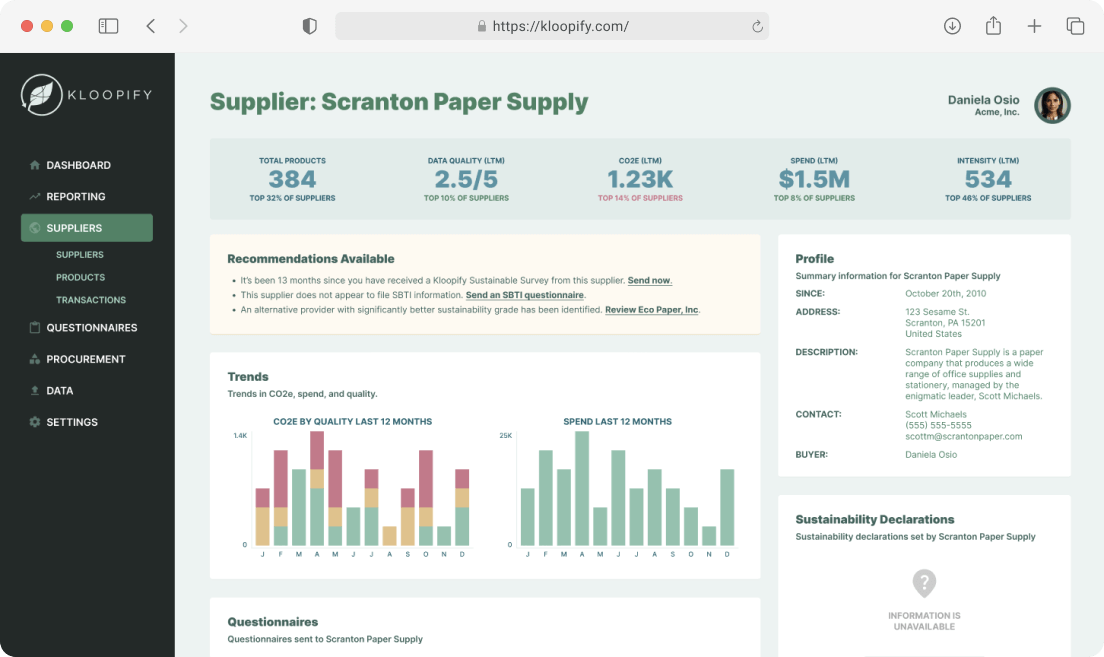
Przetwarzanie big data z Apache Spark przyspieszyło podejmowanie decyzji inwestycyjnych i zapewniło skalowalną infrastrukturę dla rosnących wolumenów danych oraz rozwiązań machine learning
