
OpenAI's GPT-3 has revolutionized the field of natural language processing, making it possible to develop highly accurate question answering systems for nearly any business application. But, tapping into this technology yourself can be intimidating. Are you struggling to choose the right training data for your NLP questions answering system? Wondering what the limitations are? Unsure where to even get started?
This article will equip you with the knowledge you need to answer these questions, so you can start building your own powerful, scalable NLP question answering system!
What is an NLP question answering system?
A natural language processing (NLP) question-answering system uses AI to understand the meaning and context of questions posed in natural language and provides accurate and relevant answers.
Unlike traditional keyword-based approaches to information retrieval, NLP question-answering systems can provide accurate answers even when the exact keywords or phrases are not present in the question.

For example, a keyword-based approach might return a list of documents that contain the phrase "New York City," but it may miss a document that talks about the "Big Apple," which is a common nickname for New York City. In contrast, an NLP question-answering system can understand that "Big Apple" is a colloquial term for New York City and return a relevant answer even if the exact phrase "New York City" does not appear in the document.
At its core, an NLP system relies on open domain question answering to provide a concise answer to the user’s question along with, if requested, a set of relevant documents.
NLP question answering systems use cases
More and more, NLP QA systems are being leveraged by businesses to automate business processes, provide enhanced levels of customer service, and even act as the foundation for new market-ready products.
To accomplish this, businesses can train their own custom NLP QA systems with unique data sets relevant for their specific application. For example, you could create an NLP question answering system for applications such as:
- Customer service: Provide automated customer service solutions to answer customer inquiries quickly and accurately without the need for human intervention.
- Healthcare: An NLP question answering system can be used to provide patients and doctors with a quick means of finding answers to medical questions. The system can be trained to understand medical terminology and answer questions about symptoms, treatments, and diagnoses.
- Ecommerce: NLP question-answering systems can be used to provide personalized product recommendations based on natural language questions about a product or service, helping to improve conversion rates on eCommerce sites.
- BI data retrieval: An NLP system can dramatically simplify the process of pulling reports and analyzing business data. Instead of spending time learning how to pull complex reports, you could simply ask a question in natural language and receive an answer.
- Academic research: Archives typically hold vast amounts of data that can be difficult to wade through. NLP systems provide an easier way for academics to conduct research and find relevant data sources.
- Developer documentation: Natural language engineering could be used to build a platform for developers to ask questions about their development projects in natural language and receive an automated response with the relevant information, eliminating the need to search through long documentation manually.
Challenges of implementing a question answering system
Using an NLP QA system doesn’t come without its challenges. Teams looking to leverage a natural language model to build a QA system should consider challenges such as:
- Limited context: Most NLP question answering systems rely on embedding-based methods to split up training data into “chunks.” This helps process the data more efficiently, but it can cause the system to lose some of the context of the information. The extent to which this is an issue will depend on the type of training data you’re using and how large your chunks of data are.
- Big data requirements: Generating accurate matches between questions and relevant answers requires large amounts of training data. Collecting the data may be relatively straightforward, but organizing and preprocessing the data can be a challenge. This is especially true for specialized domains that may require experts to be brought in to understand and organize the data effectively.
- Quality of embeddings: The quality of your NLP QA system is dependent on the quality of your embeddings. One piece of this is making sure the data is properly preprocessed, cleaned, and organized, but another piece is how well the embedding model you are using works. It can take some work to find the right embedding model and set of parameters that work with your specific data set.
- High startup costs: There are some significant costs associated with getting your NLP system built. Most of these costs will be in preprocessing your data set. Depending on the size and complexity of the data, you could be looking at devoting significant resources to effectively organize and clean your data set before it is ever ready to be used.
By leveraging OpenAI's natural language question answering API, you can reduce the challenges associated with building an NLP QA system. Let's see how.
Benefits of OpenAI natural language question answering
OpenAI's API reduces the cost, complexity and simplifies the process of building an NLP question answering system by providing:
- Access to state-of-the-art AI models: OpenAI provides access to state-of-the-art AI models, including the GPT family of models. These models have been pre-trained on vast amounts of text data and can be fine-tuned on specific domains or tasks, such as question answering. By using these models, you can take advantage of the latest advances in AI research to develop a more accurate and effective question answering system.
- Easy integration with APIs: OpenAI provides APIs that make it easy to integrate their AI models into your own question answering system. With just a few lines of code, you can send a question to an OpenAI API and receive a relevant answer. This makes it easy to incorporate AI capabilities into your existing applications without the need for extensive development work.
- Fast and scalable: OpenAI is designed to be fast and scalable, so it can handle large volumes of requests and provide near-real-time responses. This makes it well-suited for applications where speed and scalability are important, such as customer service chatbots or search engines.
8 steps to build an NLP question answering system using OpenAI
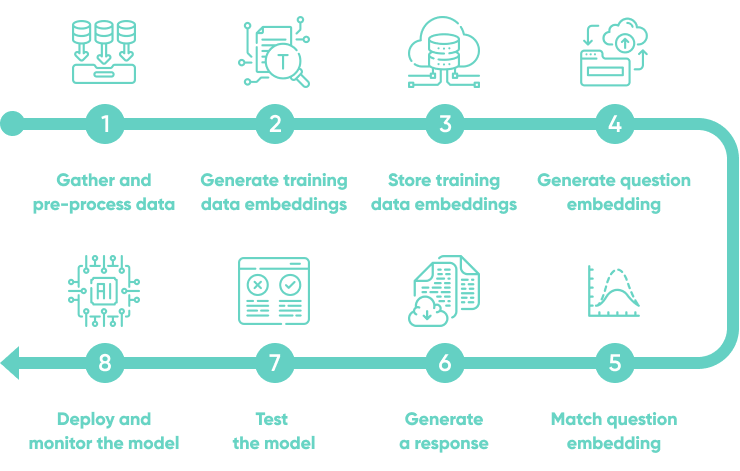
Building a QA system with OpenAI can be intimidating, but it doesn't have to be. With the right tools and understanding of the process, anyone can create an effective natural language-based QA system.
In this section, we'll show you how to get started using OpenAI's GPT models, from data selection and fine-tuning to final testing. By the end, you'll have a clear path forward to build a QA system of your own.
Gather data and pre-process the training data
The first step to build an NLP QA system is to collect and pre-process the system’s training data. To do this, you will need to identify your training data. Think about the types of questions you need your QA system to be able to answer, and where this knowledge is stored. Consider sources such as:
- Web pages
- Internal databases
- Video and audio transcripts
- News articles
- Books
- Social media posts
- Open-source libraries
- Structured data sources
Depending on the data you choose to use, you may need to preprocess it to reduce complexity and improve the accuracy of the model. This includes cleaning the data to remove any noise or duplicate information. In the next step we’ll do further preprocessing to get the data into the right format to be used by the question answering system.
PRO TIP: To achieve better results, take the time to thoroughly preprocess your data sets by:
- Removing irrelevant text: Any data that is irrelevant to your QA system should be deleted to help ensure optimal results. For example, if data was scraped from a website it might contain irrelevant text like ads or cookie notices.
- Splitting your text into sentences or paragraphs: It is worth experimenting with different lengths in order to best capture the meaning of the content. We’ll talk more about converting these into embeddings in the next section!
Generate embedding vectors
Now that you have clean data, we need to organize the data in a way that’s usable by the system. You likely have a large set of data - one that’s too large to have OpenAI process through all of it every time a user asks a question.
So, to solve this problem, we need a way to search through our data set, find the most relevant information based on the user query, and then feed just that information to OpenAI to answer the user’s question.
To accomplish this, we will use what are called embeddings. Essentially, an embedding is a vector (list) of floating point numbers that is used to represent the relatedness of text strings. First, we’ll separate our related data into “chunks.”
PRO TIP: Chunks of data should be large enough to contain enough information to adequately answer a user question but small enough to feed into a GPT-3 prompt. Generally, a paragraph of text is appropriate for each “chunk.” However, depending on the use case, you may want to separate your data by individual sentences. These chunks of data will then be processed and turned into vector embeddings that will tell us how related they are to each other. The actual process to split up the data into chunks and turn these can be done with a [pre-trained OpenAI embedding model](https://platform.openai.com/docs/guides/embeddings/use-cases). The output will be an embedding vector for each chunk of data.
Store generated embeddings
Most likely you’ll want to store your generated vector embeddings in a vector search engine database such as Pinecone or Faiss. This will help you to efficiently retrieve the most relevant sentences for a given user query.
Your database should be designed to store the sentence embeddings and their associated metadata. The metadata could include labels that identify the source of the sentence, the language it is written in, the sentiment associated with it, and any other relevant information.
PRO TIP: When storing embeddings in a vector search engine database, make sure to index the embedding vectors based on the context and keywords that the user is likely to use when asking their question. This will help the vector search engine to quickly find the most appropriate answer to the user's query.
Generate embedding for questions
With your training data organized and stored in a database, you now need to contend with how you will transform each natural language question into a format that can be compared against the embeddings in your database.
We will accomplish this by generating embeddings for user queries using the same embedding model that was used to generate sentence embeddings in step 2. However, instead of doing the embedding work a single time, upfront, like we did with the training data, we’ll need to do this process every time a user question is asked.
Match questions and database embeddings
Now that we have both our database of training data and questions in the format of embeddings, we can match question embeddings with the most relevant sentence embeddings in our vector database.
This “matching” is actually done by comparing the similarity of the question embedding against all of the embeddings in the database. Typically, this is accomplished with a simple cosine similarity function. However, many vector database systems also offer their own functions for retrieving most similar vectors. This matching process may identify a single embedding or more than one embedding that it determines are most relevant to the question.
Generate response with completion model
Now that the vector database has found the most relevant embeddings, we feed them into OpenAI’s GPT-3 completion model, so it has the information it needs to answer the user’s question.
Ideally we provide OpenAI’s completion model with the right set of information it can use to answer the user’s question but not too much unrelated information that it would waste time processing through. This may require some fine tuning!
After the completion model has been fed the right embeddings, it will generate a complete, relevant, and grammatically correct answer to the user’s question.
PRO TIP: Intelligent systems like this can only provide meaningful answers if the information they need to answer the question is available and accurately identified in the training data. If you find you aren’t getting an appropriate answer at this stage, revisit your training data to see if you need to augment or modify it.
Test the model
At this point you have successfully applied natural language processing to the user’s question and provided what is hopefully an appropriate answer back to the user. You’re off to a great start at building an NLP QA system with OpenAI.
Now you should test the QA system more thoroughly by providing it with a set of test questions and evaluating the quality, accuracy, and relevance of the responses. As you conduct testing, modify your training data or NLP model until you are satisfied with the results.
PRO TIPS: - Use metrics such as precision, recall, and F1 score to measure the system’s performance - Test whether or not the QA system is taking into account the context of the user’s question appropriately - Have the QA system answer questions that are complex and don’t have a straightforward answer to see how well it responds - Try asking questions that the QA system shouldn’t be able to answer to ensure it isn’t prone to hallucinating answers
Deploy & monitor the model
Once you are satisfied with the performance of the QA system, you can deploy it to a production environment. This might involve setting up an API to receive user queries, integrating the system with your website or application, or configuring the system to scale up or down as needed.
As part of your deployment, you should implement monitoring tools that will help you ensure the model is performing as expected in production. As you observe its behavior, you may want to conduct additional testing or retrain the model with new data, modify how the data is stored and indexed or even make changes to the search algorithm to improve the model’s performance.
PRO TIP: Deploying such a system is not a “one and done” project. It requires continuous maintenance in order to perform well. Ensure you have planned for this if you want your model to function properly long-term.
Conclusion
OpenAI-powered NLP question answering systems have clear advantages over traditional keyword-based approaches. Deep learning and natural language processing can accurately answer complex queries, with pre-trained models and fine-tuning allowing for fast deployment. OpenAI-embedded NLP question answering systems can bring productivity and customer experience improvements, as well as competitive advantages to businesses who are willing to embrace this new technology.
If you're looking for help developing an OpenAI-powered NLP QA system, consider our AI development services. Our team can help you put together a comprehensive AI strategy and guide you through the development process. With our custom software development company, you can leverage the power of GPT-3 OpenAI API to build an accurate NLP QA system that gives you a competitive edge.





![6 Proven GPT-3 Open-Source Alternatives [2023 Comparison]](/uploads/blog/gpt3-open-source-alternatives/gpt3-open-source.png)