Big Data ETL for Real Estate Investment Decisions
Apache Spark’s big data processing speeded up investment decision-making and provided scalable infrastructure for growing data volumes and machine learning solutions


AI is only as good as the data behind it. We design and build cloud data platforms — ingestion, warehousing, governance — and deliver data pipelines up to 90% faster.






We’ll help you save time and resources. Avoid errors, apply best practices, and deploy high-performance Big Data solutions.
Our experts assess the project you’re planning or review your existing deployment. Discover best practices, assess design trade-offs, and flag potential pitfalls to ensure that your team’s projects are well designed and built.
Implement modern data architectures with cloud data lake and/or data warehouse. Develop data pipelines 90% faster and significantly reduce the amount of time you spend on data quality processes.
Data governance is one of the single most important data initiatives. We help build data governance foundations and set up the proper tools to meet CCPA, GDPR, and other legal policies requirements.
Our experts can help you leverage the scalability of cloud-native data platforms and gain an advantage with flexible pricing, storage, and performance of your data processing.
Hire a dedicated remote team
Scale up with remote engineers
Engage technology experts
Data Engineering Expertise
Leverage our expertise at every stage of the process: data collection, data processing and the Extract, Transform and Load (ETL) process, data cleaning and structuring, data visualisation and building predictive models on the top of data.
Time and Cost Savings
Hiring new employees with the proper skills takes too much time and is expensive — that’s assuming you can even find them in a very competitive job market. We have experts who are ready to work on your data engineering project.
Before we build an AI agent or automation, we make sure your data can feed it. Clients who start with our data engineering team move to production AI faster — see our AI development services.
Engage quality
tech professionals
We are driven by 15+ years of experience in IT staff augmentation and engineering software solutions.
Fast process:
CVs within 3 days
Time and cost savings - receive first CVs of our specialists and start interviewing candidates.
Risk-free
2-weeks trial
To get rid of any doubts, check the quality of your team with no obligation to pay with 2-weeks trial.
Our business strategy is simple: if our customers' business is booming, we are growing too
We take project ownership and responsibility for decisions that were taken during the development
The bottom-line results of your project are the only metric that really matters to us
SoftKraft have proven are way ahead of the curve. The team impressed us with their ability to speak at the business strategy level.

SoftKraft has been a very reliable partner for us. They took over our system infrastructure in a short time and managed to handle it in a professional and reliable way.

We were very impressed with their commitment to achieving a high-quality outcome and their willingness to explore a variety of possible solutions for our goal.








Apache Spark’s big data processing speeded up investment decision-making and provided scalable infrastructure for growing data volumes and machine learning solutions
Using Apache Kafka and OpenShift to build a real-time streaming solution enabling gamers to optimize their performance and monetization strategies in a gaming community

Installing Big Data-enabled BI Tool in company IT infrastructure allowed analysts to interactively examine business data in near real time as well as equipped them to make faster and better investment decisions

Data Engineering and Data Science are complementary.
Data Engineering ensures that data scientists can look at data security and consistently. Data Engineers handle many core elements of Data Science, such as the initial collection of raw data and the process of cleansing, sorting, securing, storing, and moving that data.
Data Science combines computer science, statistics, and mathematics. Data Scientists apply a combination of algorithms, tools, and machine learning techniques like predictive analytic to help you to extract knowledge from the data.
Start with a free consultation — we'll review your current data architecture and goals. From there, you choose the engagement model that fits:
At a high level, Big Data Engineering has a generic architecture that applies to the majority of businesses:
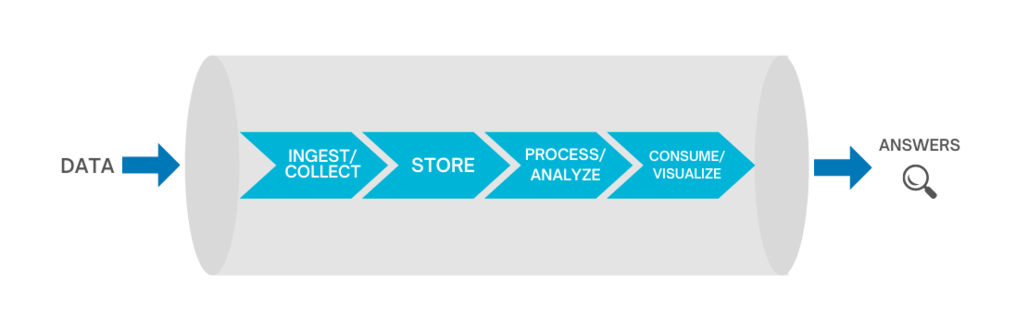
You need your Big Data setup to handle all incoming data streams, whether structured, unstructured, or semi-structured. The incoming data is prioritized and categorized for a smooth flow into further layers down the line. Data ingestion can happen through real-time streaming or batch jobs. We typically use Apache Kafka and AWS/GCP specific solutions (GCP Pub/Sub, GCP Big Query, GCP Cloud Storage, AWS Redshift, AWS S3, AWS Athena, etc) for creating data ingestion pipelines.
After raw data is ingested, the extracted data should be stored somewhere. The storage solution should be in line with the data ingestion requirement of your business ecosystem.
The processing layer where the analytical process begins, where data is needed for analysis is selected, cleaned, formatted for further analysis and modeling. The goal is to discover useful information, suggest conclusions and support decision-making. Data Processing on AWS by access characteristics:
This layer is everything to do with a graphical representation of information and value gained through analysis. Using rich charts, graphs, and maps, the tools in this layer help present a compelling story for a decision to be made by your leadership team.
We typically use Amazon QuickSight or Tableau, see our article Embedded Analytics: Amazon QuickSight vs Tableau





