
Building a modern streaming architecture ensures flexibility, enabling you to support a diverse set of use cases. It abstracts the complexity of traditional data processing architecture into a single self-service solution capable of transforming event streams into analytics-ready data warehouse. And, it makes it easier to keep pace with innovation and stay ahead of the competition.
At SoftKraft we help startups and SMEs unlock the full potential of streaming data architectures. Business and technology leaders engage us to implement projects or augment their teams with data engineering experts and Kafka consultant.
In this article, you will learn how do you decide which popular stream processing tools to choose for a given business scenario, given the proliferation of new databases and analytics tools.
What is Streaming Data Architecture?
A streaming data architecture is capable of ingesting and processing massive amounts of streaming data from a variety of different sources. While traditional data solutions focused on batch writing and reading, a streaming data architecture consumes data as it is produced, persists it to storage, and may perform real-time processing, data manipulation, and data analysis.
Initially, stream processing was considered a niche technology. Today it's difficult to find a modern business that does not have an app, online advertising, an e-commerce site, or products enabled by the Internet of Things. Each of these digital assets generates real-time event data streams. There is a growing appetite for implementing a streaming data infrastructure that enables complex, powerful, and real-time analytics.
Streaming data architecture helps to develop applications that use both bound and unbound data in new ways. For example, Netflix also uses Kafka streams to support its recommendation engines, combining streamed data and machine learning.
Streaming Data Architecture Use Cases
At smaller scales, traditional batch architectures may suffice. However, streaming sources such as sensors, server and security logs, real-time advertising, and clickstream data from apps and websites can generate up to a Gb of events per second.
Stream processing is becoming a vital part of many enterprise data infrastructures. For example, companies can use clickstream analytics to track web visitor behavior and tailor their content, while ecommerce historical data analytics can help retailers prevent shopping cart abandonment and show customers more relevant offers. Another common use case is Internet of Things (IoT) data analysis, which involves analyzing large streams of data from sensors and connected devices.
Benefits of data stream processing
Stream processing provides several benefits that other data platforms cannot:
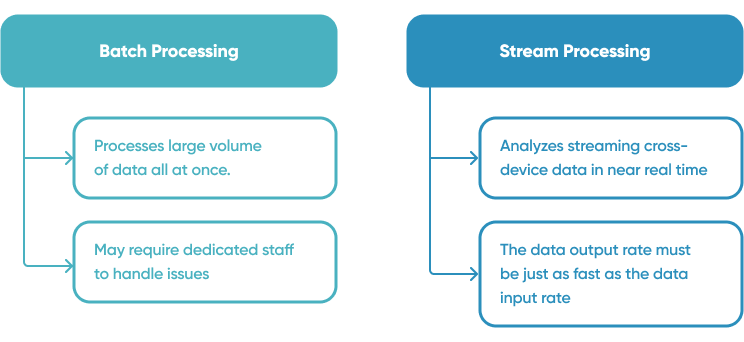
Handling never-ending streams of events natively, reducing the overhead and delay associated with batching events. Batch processing tools need pausing the stream of events, gathering batches of data, and integrating the batches to get a conclusion. While it is difficult to aggregate and capture data from numerous streams in stream processing, it enables you to gain instant insights from massive amounts of streaming data.
Processing in real-time or near-real-time for up-to-the-minute data analytics and insight. For example, dashboards that indicate machine performance, or just-in-time delivery of micro-targeted adverts or support, or detection of fraud or cybersecurity breaches.
Detecting patterns in time-series data. Detection of patterns over time, such as trends in website traffic statistics, requires data to be processed and analyzed continually. This is made more complex by batch processing, which divides data into batches, resulting in certain occurrences being split across two or more batches.
Simplified data scalability. Growing data volumes might overwhelm a batch processing system, necessitating the addition of additional resources or a redesign of the architecture. Modern stream processing infrastructure is hyper-scalable, with a single stream processor capable of processing Gigabytes of data per second.
Developing a streaming architecture is a difficult task that is best accomplished by the addition of software components specific to each use case – hence necessitating the need to "architect" a common solution capable of handling the majority, if not all, envisioned use cases.
Streaming data challenges
Real-time data streaming systems require new technologies and process bottlenecks. The increased complexity of these systems can lead to failure when seemingly innocuous components or processes become slow or stall. Here are the streaming data challenges today's organizations face, and solutions:
Reliance on centralized storage and compute clusters
Modern real-time data streaming technologies, such as Apache Kafka, are designed to support distributed processing and to minimize coupling between producers and consumers. Deployment too tightly tied to one central cluster (i.e. traditional Hadoop stack) can suffocate project and domain autonomy. As a result, streaming adoption and data consumption will be constrained.
Solution
Containerization, which allows for greater flexibility and domain independence, is used in a distributed deployment architecture to achieve this.
Scalability bottlenecks
As data sets grow bigger, operations naturally become a more significant problem. For example, backups take significantly longer and consume a significant amount of resources. Rebuilding indexes, defragmenting storage, and reorganizing historical data are all time-consuming and resource-intensive operations that require significant resources.
Solution
Check the production environment loads. If you test run the expected load of the previous 3 months of the data, you can find and fix problems before going live.
Business integration hiccups
In many cases, the enterprise consists of many lines of business and application teams, each focused on its own mission and challenges. This works for a while until each group needs to integrate and exchange real-time event data streams.
Solution
To federate the events, multiple integration points may be required.
4 Key Components of a Streaming Data Architecture
A streaming data architecture is a set of software components designed to handle large streams of raw data from various sources:
Message Broker (Stream Processor)
The stream processor collects data from its source, converts it to a standard message format, and then streams it continuously for consumption by other components. A storing streaming data component, such as a data warehouse/data lake, an ETL tool, or another type of component are examples of such components. Stream processors have a high throughput, but they don't do any data transformation or task scheduling.
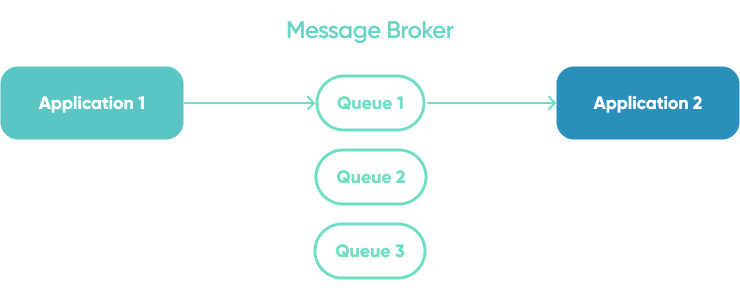
Message Broker can act as a proxy between two applications where communication between them is achieved using queues. In such case we refer to it as point-to-point broker.
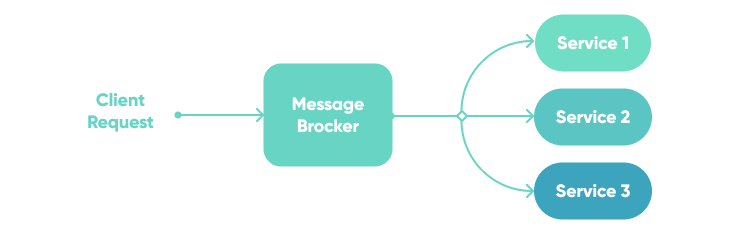
If one application is broadcasting a single message to multiple applications, we say that broker acts in Publish/Subscribe model
Popular stream processing tools:
Batch processing and real-time ETL tools
In data-intensive organizations, process streaming data is an essential component of the big data architecture. There are many fully managed frameworks to choose from that all set up an end-to-end streaming data pipeline in the cloud to enable real-time analytics.
Example managed tools:
Streaming Data Storage
Organizations typically store their streaming event data in cloud object stores to serve as operational data lake due to the sheer volume and multi-structured nature of event streams. They offer a low-cost and long-term solution for storing large amounts of event data. They're also a flexible integration point, allowing tools from outside your streaming ecosystem to access data.
To learn more, check out Data Lake Consulting services.
Data Analytics / Serverless Query Engine
With data processed and stored in a data warehouse/data lake, you will now need data analytics tools.
Examples (not exhaustive):
- Query engines – Athena, Presto, Hive, Redshift Spectrum, Pig
- Text search engines – Elasticsearch, OpenSearch, Solr, Kusto
- Streaming data analytics – Amazon Kinesis, Google Cloud DataFlow, Azure Stream Analytics
Streaming architectures patterns
Streaming architectures patterns help build reliable, scalable, secure applications in the cloud:
Idempotent producer
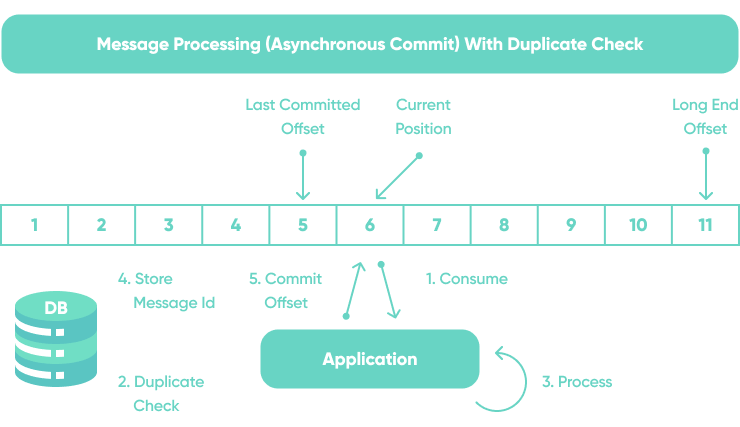
The event streaming platform knows nothing of the business logic so how can you deal with duplicate events when reading from an event stream?
The idempotent producer pattern is most commonly used to deal with duplicated events in an input data stream.
For example in Apache Kafka, with ProducerConfig configuration:
enable.idempotence=true
acks=allEach producer gets assigned a Producer Id (PID) and it includes its PID every time it sends messages to a broker. Additionally, each message gets a monotonically increasing sequence number.
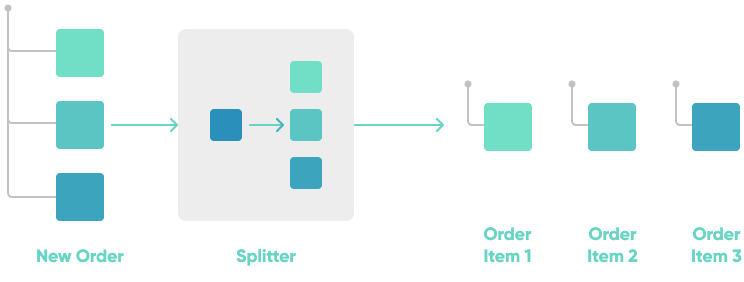
Event splitter
Many data sources produce messages that consist of multiple elements. The event splitter pattern can be used used to split a business event into multiple events. For example, e-commerce order events can be split into multiple events per order item (for analytics purposes).
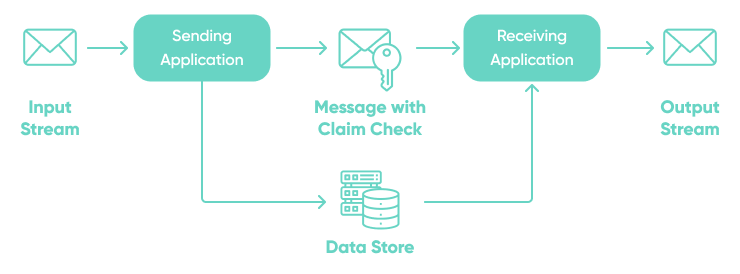
Claim-check pattern
Often a messaging-based architecture must be capable of sending, receiving, and manipulating large messages. These use cases can be related to image recognition, video processing, etc. Sending such large messages to the message bus directly is not recommended. The solution is to send the claim check to the messaging platform and store the payload to an external service.
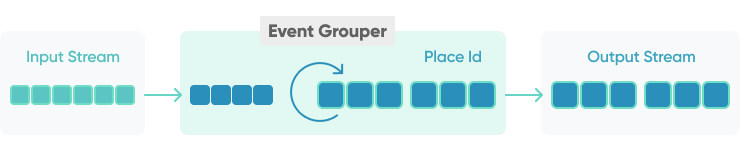
Event grouper
Sometimes Events become significant only after they've happened several times. For example, parcel delivery will be attempted three times before we ask the customer to collect it from the depot. How can we wait for N logically similar events?
The solution is to consider related events as a group. For this, we need to group them by a given key, and then count the occurrences of that key.
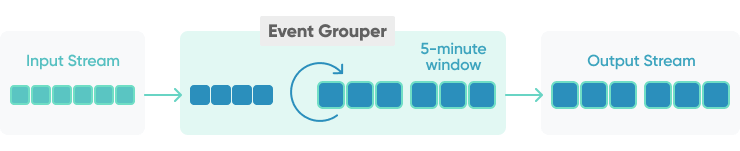
For time-based grouping, we can group related events into created automatically time windows, for example, 5 minutes or 24 hours.
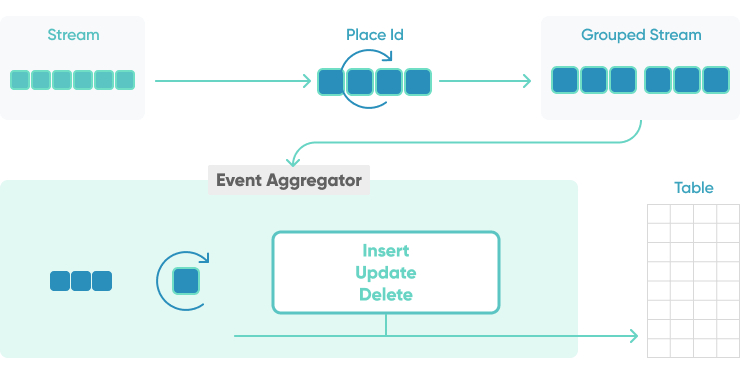
Event aggregator
Combining multiple events into a single encompassing event, calculate the average, median, or percentile on the incoming business data, a common task in event streaming and real-time analytics. How can multiple related events be aggregated to produce a new event?
We can combine event grouper and event aggregator. The grouper prepares the input events as needed for the subsequent aggregation step, e.g. by grouping the events based on the data field by which the aggregation is computed (such as order ID) and/or by grouping the events into time windows (such as 5-minute windows). The aggregator then computes the desired aggregation for each group of events, e.g., by computing the average or sum of each 5-minute window.
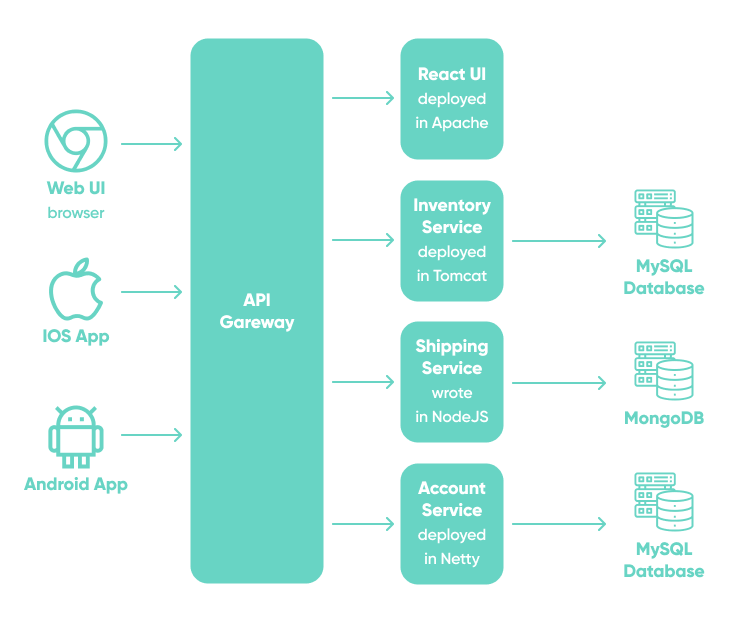
Gateway routing
When a client requires the consumption of multiple services, setting up a separate endpoint for each service and having the client manage each endpoint can be challenging. For example, an e-commerce application might provide services such as search, reviews, cart, checkout, and order history. Each service has a unique API with which the client must communicate, and the client must be aware of all endpoints in order to connect to the services.
If an API is changed, the client must also be updated. When a service is refactored into two or more distinct services, the code in both the service and the client must change.
Gateway routing allows the client applications to know about and communicate with a single endpoint.
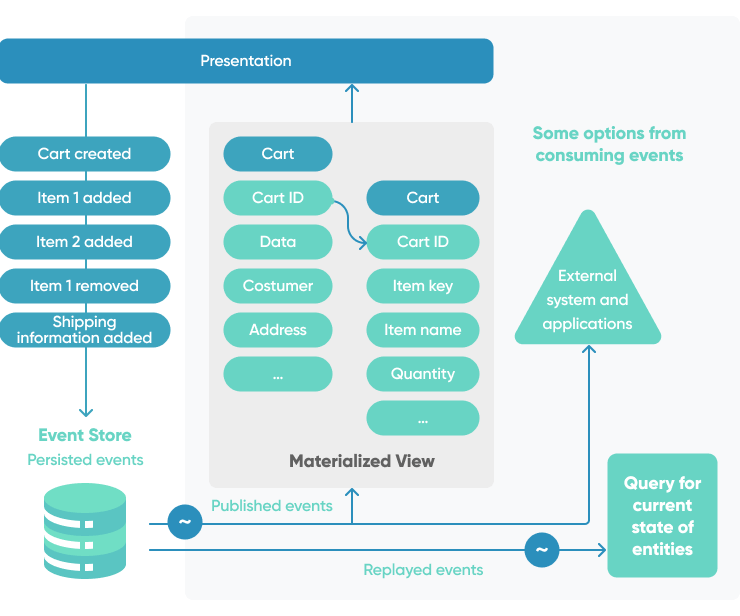
CQRS
It is common in traditional architectures to use the same data model for both querying and updating databases. That's straightforward and effective for basic CRUD operations. However, in more complex applications, this approach can become cumbersome. For example, the application may run a variety of queries, returning data transfer objects of various shapes.
Command and Query Responsibility Segregation (CQRS) is a pattern for separating read and update operations in a data store. CQRS can improve the performance, scalability, and security of your application. Migrating to CQRS gives a system more flexibility over time, and it prevents update commands from causing merge conflicts at the domain level.
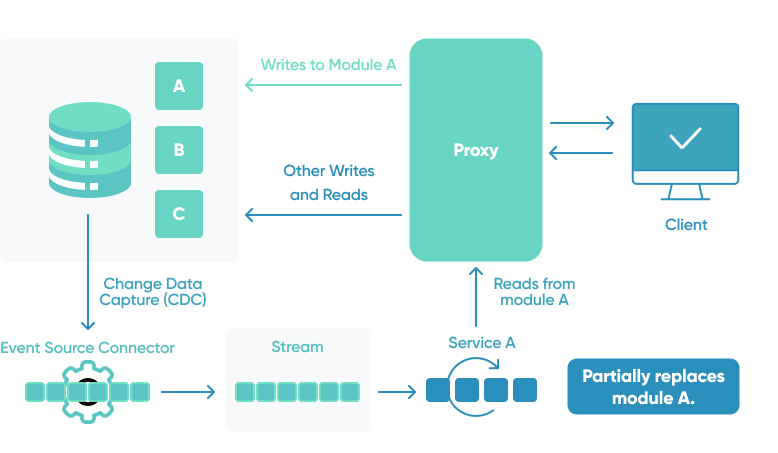
Strangler Fig pattern
As systems age, the development tools, hosting technology, and even system architectures on which they were built can all become obsolete as systems age. The complexity of these applications can increase dramatically as new features and functionality are added, making them more difficult to maintain and add new features to.
Replacing a complex system from the ground up can be a huge undertaking. Often, you will need a gradual migration to a new system, with the old system remaining in place to handle features that have not yet been migrated.
You can use the Strangler Fig pattern to incrementally migrate a legacy system by gradually replacing specific pieces of functionality with new applications and services. Eventually, the old system's functions will be completely replaced by the new system, making it possible to decommission the old system.
Conclusion
The growing popularity of streaming data architectures reflects a shift in the modern data platforms development from a monolithic architecture to a decentralized one built with microservices.
This type of architecture is more flexible and scalable than a classic DB-centric application architecture and it factors the time an event occurs into account, which makes it easier for an application’s state and processing to be partitioned and distributed across many instances.





