![Apache Kafka Use Cases [with Kafka Architecture Diagrams]](/.netlify/images?url=_astro%2Fapache-kafka-use-cases.DJ0_hPhf.png&w=740&h=416&dpl=6a2dc680a466470009259c33)
Today, we all expect web applications to reply promptly, if not instantly, to user queries. As applications cover more aspects of our everyday life, it becomes increasingly difficult to provide users quick response times.
Caching is used to tackle a wide variety of those problems, however, in many situations, applications require real-time data. On top of that we data to be aggregated, enriched, or otherwise transformed for further consumption or follow-up processing. In these use cases, Kafka comes in helpful.
At SoftKraft help startups and SMEs unlock the full potential of Kafka streaming platform. We’ll help you save time and resources. Avoid errors, apply best practices, and deploy high-performance streaming platforms that scales. Learn more about our Kafka consulting
What is Apache Kafka?
Apache Kafka is a distributed data store optimized for ingesting and lower latency processing streaming data in real-time. It can handle the constant inflow of data sequentially and incrementally generated by thousands of data sources.
Kafka is often used to develop real-time streaming data pipelines and adaptive applications. It integrates messaging, storage, and stream processing to enable the storage and analysis of historical as well as real-time data.
Kafka was created at LinkedIn in 2010 by a team led by Jay Kreps, Jun Rao, and Neha Narkhede. Their initial objective was to achieve low-latency ingestion of massive amounts of event data from the LinkedIn website and infrastructure into a lambda architecture.
Key components of Kafka
Kafka combines two messaging models, queuing and real-time publish-subscribe, in order to provide consumers with the key benefits of both. Its core components are:
- Broker - Apache Kafka runs as a cluster on one or more servers across multiple data centers. A broker is a Kafka cluster instance.
- Producers - client applications that publish (write) events to Kafka the brokers.
- Consumers - that subscribe to (read and process) these events.
- Kafka Topic - A Topic is a category/feed name to which messages are stored and published. Producer applications write data to topics and consumer applications read from topics.
Key Kafka functionalities
Kafka integrates messaging, storage, and stream processing to enable the storage and analysis of historical as well as real-time data pipelines. kafka is often used as a message broker solution, which is a platform that processes and mediates communication between applications.
Kafka's users are provided with three primary functions:
- Publish-subscribe messaging system
- Storing data streams in a fault-tolerant durable way
- Large scale message processing in real-time
A streaming platform establishes many benefits for enterprise distributed systems:
Large and elastic scalability regarding nodes, volume, and throughput. Horizontally scalable replication in public cloud and hybrid deployments.
Deployment using containers Deploy as required, on-premises, in the public cloud, or in a hybrid environment.
Independent and decoupled business services. Move data to where it is needed using simple event driven architecture which allows for independent speed of processing between different producers/consumers.
Integrability with all kinds of applications and systems. Connect anything: programming language, REST APIs, proprietary tools, and legacy applications.
Maintain tenant data isolation Kafka provide access control lists (ACLs) enforced at the cluster-level and specify which users can perform which actions on which topics.
What are the Apache Kafka use cases?
Kafka is used by thousands of companies including over 60% of the Fortune 100. enables organizations to modernize their data strategies.
Discover how Kafka is used by organizations across a range of industries, from computer software to financial services, health care, and government and transportation.
User activity tracking
Apache Kafka is often used as a user activity tracking pipeline. Each event that occurs in the application can be published to the dedicated Kafka topic. User clicks, registrations, likes, time spent on certain pages by users, orders, etc. – all these events can be sent to Kafka’s topics.
Kafka Architecture Diagram at LinkedIn
LinkedIn utilizes Apache Kafka to manage user activity data streams and operational metrics. This technology underpins a variety of LinkedIn products, including LinkedIn Newsfeed and LinkedIn Today, as well as streaming analytics systems, such as Hadoop.
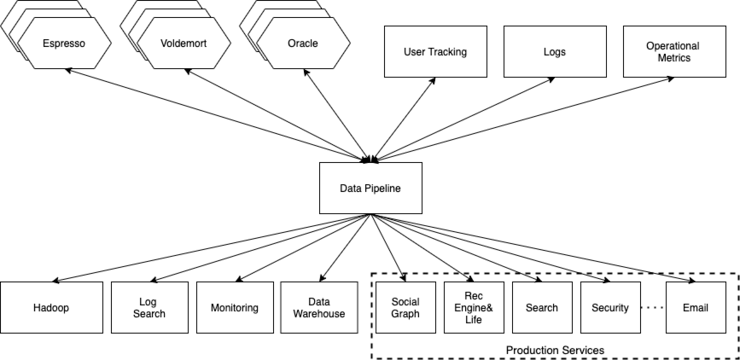
Source: Apache Kafka at LinkedIn
Other similar Kafka use cases
Wikimedia Foundation uses Kafka as the base of their event streaming platform for both production and analytics, including reactive Wikipedia cache invalidation and reliable ingestion of large data streams. See Wikimedia Event Platform
HackerRank, a programmer’s social network, makes use of Kafka as a platform for event driven architecture. All application activity is published to Kafka, which is subscribed to by a wide variety of internal services.
Coursera uses Kafka to power education at scale, serving as the data pipeline for real-time learning analytics/dashboards.
"Find someone" is Mate1.com's motto, and that's exactly what it helps millions of singles do as a dating website. Kafka powers their news and activity feeds, automated review systems, real-time notifications, and log distribution.
Real-time data processing
Many modern systems require data to be processed as soon as it becomes available. Many users of Kafka process data in processing pipelines consisting of multiple stages, where raw input data is consumed from Kafka topics and then aggregated, enriched, or otherwise transformed into new topics for further consumption or follow-up processing.
Kafka Architecture Diagram at Netflix
Netflix Studio Productions and Finance Team embraces Apache Kafka as the de-facto standard for its eventing, messaging, and stream processing needs. Kafka is at the heart of Netflix Studio event driven architecture and with it, the film industry.
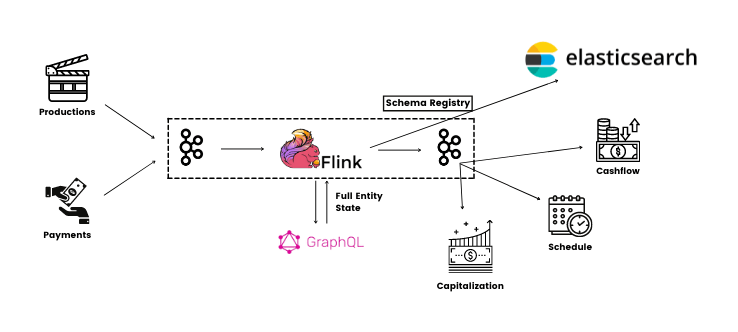
Other similar real-time processing use cases
TikTok (ByteDance) utilizes Kafka as a data hub for the collection of events and logs in support of a variety of services such as large scale message processing and activity tracking.
Skyscanner, a large travel search engine, uses Kafka for real-time log and event ingestion. It serves as the central point of integration for all data stream processing and data flow.
Event sourcing
Kafka Streams is an excellent fit for developing the event handler component of an application that utilizes CQRS for event sourcing. Kafka can maintain a commit log and this is precisely how a traditional database is constructed beneath the surface.
Applications moving to a CQRS-based pattern using Kafka Streams do not have to worry about fault tolerance, availability, or scalability. This is all provided by the Kafka.
Kafka Architecture Diagram at Grab
Grab, a major food delivery platform is an example of large Kafka deployment at TB/hour scale. Kafka handles mission-critical event logs, event sourcing, and stream processing architectures. Both stateful and stateless applications built over these logs by backend engineers, machine learning engineers, data scientists, and analysts support real-time, near-realtime, and analytical use cases across our business lines, from ride-hailing and food delivery.
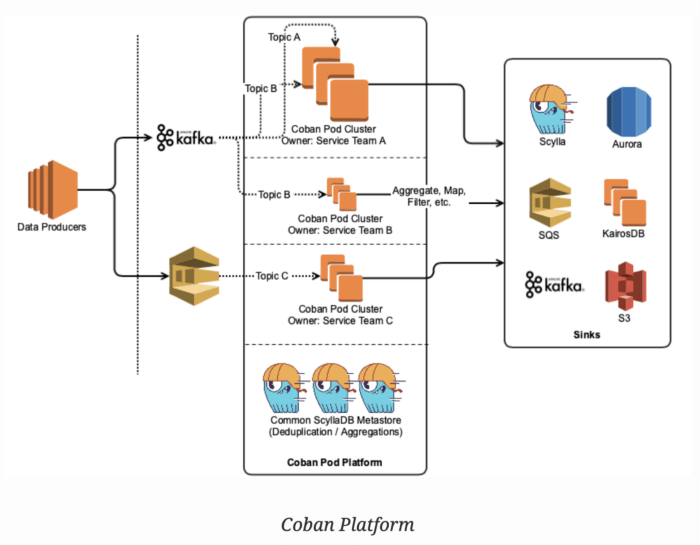
Other similar Kafka use cases
Wix, the major website builder with millions of users, successfully integrated Event Sourcing in their architecture in several projects such as Invoices, Stores, and some others. See Event Sourcing at Wix
Zalando, the leading online fashion retailer in Europe, uses Kafka as an ESB (Enterprise Service Bus), which helps us in transitioning from a monolithic to a microservices architecture. See project Nakadi Event Broker, a distributed event bus that implements a RESTful API abstraction on top of Kafka-like queues.
Centralized Data Log
As distributes systems grow, Managing or accessing the log becomes difficult. Kafka can act as an external commit-log. The log helps in data replication between nodes and serves as a re-syncing mechanism. A common solution is to centralize the logs in an enterprise-grade logging system (CLS).
Kafka Architecture Diagram at Twitter
Twitter, a well-known online social networking service and platform, makes use of Kafka in a similar way, essentially enabling users to send and receive tweets. Registered users can read and post tweets on this platform, while unregistered users can only read tweets.
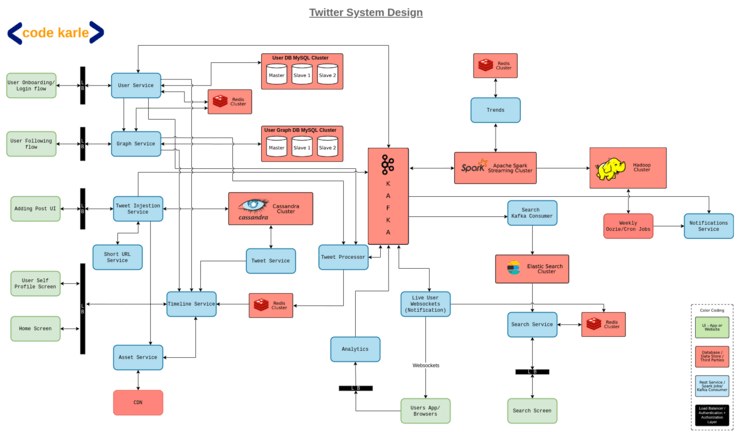
Source: Twitter System Design
Other similar Kafka use cases
Loggly, one of the world's most popular log aggregation solution, provides a cloud-based log management service that helps DevOps and technical teams make sense of the massive quantity of logs. Apache Kafka is used as part of their log collection and processing infrastructure.
See Why Loggly Loves Apache KafkaNew Relic uses Kafka to allow you to collect all your telemetry data in one place to deliver full-stack observability. This large-scale Kafka deployment processes hundreds of gigabytes of data per second.
Conclusion - When should you use Kafka?
I believe the answer always comes down to the use case. While Kafka solves a common problem for many web-scale companies and enterprises, it is not a one-size-fits-all solution like a more traditional message broker. You can use Kafka to collect and store all of the "facts" or "events" generated by a distributed system in order to build a set of resilient data services and applications.
Kafka is a perfect choice for creating a centralized data fabric connecting all components of your system into a single business solution. If your applications exchange large volumes of data, it is very likely that Kafka is the right tool for your business needs.
You'll have to weigh the advantages and disadvantages in the end. As a real-time data processing and application activity tracking tool, Kafka is also useful as a big data technology. But Kafka should not be used for on-the-fly data transformations, data storage, or just a simple task queue, for example.