
As a Python AI Developer at SoftKraft, I’ve spent the last few years shipping production-grade generative AI applications that combine Django’s rock-solid foundation with FastAPI microservices, LangChain orchestration, Pinecone vector stores, and Retrieval-Augmented Generation (RAG) pipelines. Companies are pouring billions into AI initiatives, and the momentum is only accelerating. In my experience, Django’s scalability, rapid development cycle, and enterprise-grade security features make it an outstanding choice for building reliable AI-driven web applications that can move from prototype to production without painful rewrites.
This guide distills seven battle-tested practices I rely on daily when delivering AI web apps for EdTech platforms, enterprise knowledge bases, and intelligent automation tools.
- Why is Django a good choice for AI web development?
- 7 proven best practices for Django AI development
- 1. Speed up development with Django’s built-in features
- 2. Integrate AI services using dedicated frameworks and robust LLM patterns
- 3. Leverage vector databases to store complex model data
- 4. Use RAG to ground the model with business data
- 5. Load large data sets without atomic transactions
- 6. Use Celery async tasks for heavy data manipulation
- 7. Minimize database queries with bulk operations
- AI software development with SoftKraft
- Conclusion
Why is Django a good choice for AI web development?
From shipping multiple LLM-powered products, I can confidently say Django shines for AI web development for several practical reasons:
- Integration with AI libraries: It integrates seamlessly with TensorFlow, PyTorch, scikit-learn, and modern LLM orchestration tools like LangChain and LlamaIndex, essential for everything from data analysis to computer vision and context-aware chatbots.
- Robust security: Built-in protections against common web vulnerabilities (CSRF, XSS, SQL injection) give us peace of mind when handling sensitive user prompts and business data.
- API development: The Django Rest Framework makes it trivial to expose clean, documented endpoints for AI services, whether you’re serving NLP results or agentic workflows.
- Community and support: The massive ecosystem and excellent documentation mean we rarely get stuck, even when combining Django with bleeding-edge AI libraries.
- Rapid development: The “batteries-included” philosophy lets our team move from idea to scalable, production-ready AI application faster than many lighter frameworks.
7 proven best practices for Django AI development
Building production AI solutions with Django is highly effective when you follow practices that balance developer velocity with long-term maintainability and performance. Drawing from real client projects involving large-scale RAG systems and LLM-driven features, here are seven techniques that consistently deliver results.
Speed up development with Django’s built-in features
Django’s high-level abstractions have saved me and my team countless hours across every AI project I’ve led. Instead of reinventing the wheel, we lean heavily on its mature, production-ready components:
- Django admin: The admin interface becomes a powerful monitoring dashboard for AI models, training data, and inference logs without writing a single line of custom backend code.
- Authentication system: Out-of-the-box user management and permissions keep sensitive AI endpoints (and the data they process) securely locked down.
- Form handling: Built-in validation and cleaning make it effortless to capture user inputs for LLM prompts while maintaining data integrity.
- URL routing: Clean, declarative routing keeps your AI endpoints organized even as the feature set grows.
- Static file management and templating: The powerful templating engine lets us quickly build dynamic interfaces that display AI-generated content, charts, and real-time results.
Integrate AI services using dedicated frameworks and robust LLM patterns
In my daily work building production LLM-powered applications with Django and FastAPI, choosing the right integration strategy is critical for scalability and maintainability. While Django Rest Framework (DRF) remains excellent for building RESTful APIs that connect your Django backend to AI services, modern frameworks like LangChain and LlamaIndex have become essential for orchestrating complex LLM workflows.
LangChain excels at creating chains, agents, and memory for more sophisticated interactions, while LlamaIndex is particularly strong for context-augmented generation and indexing large document corpora. For interactive chatbots, integrating OpenAI’s models (or alternatives like Anthropic or Grok) is straightforward.
Additionally, when performance and real-time streaming are priorities (common in AI apps), I often pair Django with FastAPI microservices. FastAPI’s async capabilities and native support for Server-Sent Events make it ideal for handling LLM response streaming.
Prompt Engineering Best Practices in Django Views
A crucial lesson I’ve learned from deploying several RAG systems is treating prompt construction as production code. In Django views, I always follow these practices:
- Input sanitization: Always validate and sanitize user inputs before feeding them into prompts to prevent prompt injection attacks.
- Structured output parsing: Use Pydantic models or LangChain’s output parsers to ensure reliable JSON-structured responses from LLMs.
- Streaming responses: Implement Server-Sent Events (SSE) or WebSockets for real-time token streaming, dramatically improving perceived performance in chat interfaces.
Here’s a simplified example of a Django view using LangChain for a RAG-enhanced query:
from django.http import StreamingHttpResponse, JsonResponse
from langchain.prompts import PromptTemplate
# ... other imports (chain, vector store, etc.)
def rag_query_view(request):
query = request.GET.get('q')
# sanitize and validate query
if not query or len(query) > 500:
return JsonResponse({'error': 'Invalid query'}, status=400)
# Retrieve relevant docs via vector store, build prompt...
prompt = PromptTemplate.from_template("Context: {context}\n\nQuestion: {query}")
# chain = LLMChain(...) or LCEL chain with your RAG pipeline
def stream_response():
for token in chain.stream({"query": query}):
yield f"data: {token}\n\n"
return StreamingHttpResponse(stream_response(), content_type='text/event-stream')
This approach ensures secure, reliable, and user-friendly AI integrations.
Leverage vector databases to store complex model data
Vector databases have become indispensable for handling tasks like semantic similarity search, recommendations, and RAG systems. They allow efficient storage and retrieval of high-dimensional embeddings that traditional relational databases simply weren’t designed for.
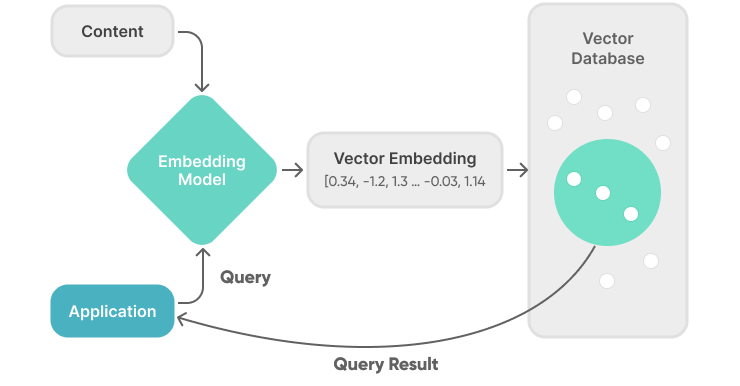
If you're using PostgreSQL, pgvector is an excellent starting point. It lets you store and query vectors directly inside your existing database using familiar SQL.
Step 1: Install Django and pgvector
Connect to your PostgreSQL server as a superuser and execute the following command to install pgvector:
CREATE EXTENSION pgvector;Once pgvector is set up, you can integrate it into your Django project. This integration allows your web applications to perform complex AI tasks like similarity searches directly from the database.
Step 2: Define a Django model
Create a model in Django to store and manage your vector data. Here’s an example model that includes a name field and a vector field:
from django.db import models
from pgvector.django import VectorField
class VectorModel(models.Model):
name = models.CharField(max_length=100)
vector = VectorField(dimensions=128)Step 3: Insert vectors
To insert vector data, you can use Django’s ORM:
VectorModel.objects.create(name="Example", vector=[0.1, 0.2, ..., 0.128])Step 4: Retrieve and search vectors
For searching similar vectors, perform a raw SQL query within Django to leverage pgvector's capabilities:
from django.db import connection
def search_similar_vectors(vector):
with connection.cursor() as cursor:
cursor.execute(""" SELECT name, vector FROM myapp_vectormodel
ORDER BY vector <-> %s
LIMIT 5;
""", [vector])
return cursor.fetchall()This function fetches the top 5 vectors closest to the input vector, utilizing pgvector's distance operator <->.
Step 5: Implement a search view
To make vector search available through your Django application, you can set up a view that handles vector search requests:
from django.http import JsonResponse
def vector_search(request):
input_vector = request.GET.getlist('vector', [])
input_vector = [float(i) for i in input_vector]
results = search_similar_vectors(input_vector)
return JsonResponse({"results": results})Choosing the right vector database: pgvector vs Pinecone
In several enterprise RAG projects at SoftKraft, we’ve used both solutions depending on scale and operational needs. pgvector shines when you’re already on PostgreSQL: zero extra services, SQL-native queries, and cost-effective for moderate workloads.
For larger-scale production systems (millions of embeddings, high query throughput, advanced metadata filtering, or hybrid search), I strongly prefer Pinecone. It’s fully managed, serverless, and removes the operational burden of managing indexes and scaling.
Example: Integrating Pinecone in Django
import os
from pinecone import Pinecone, ServerlessSpec
from django.conf import settings
pc = Pinecone(api_key=settings.PINECONE_API_KEY)
# Create index once (usually in management command or migration)
if "my-ai-index" not in pc.list_indexes().names():
pc.create_index(
name="my-ai-index",
dimension=1536, # e.g. OpenAI text-embedding-3-small
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
index = pc.Index("my-ai-index")
# Utility functions you can call from views or Celery tasks
def upsert_embeddings(vectors):
# vectors: list of (id, embedding_vector, metadata_dict)
index.upsert(vectors=vectors)
def semantic_search(query_vector, top_k=5, filter=None):
results = index.query(
vector=query_vector,
top_k=top_k,
include_metadata=True,
filter=filter
)
return results["matches"]
These utilities integrate cleanly with Django’s ORM and Celery for embedding generation and retrieval.
Use RAG to ground the model with business data
One of the biggest hurdles I’ve encountered when deploying LLMs in production is hallucinations and responses based on stale or generic knowledge. RAG has become our standard solution at SoftKraft for building trustworthy AI systems that actually understand company-specific data.
The setup looks something like:
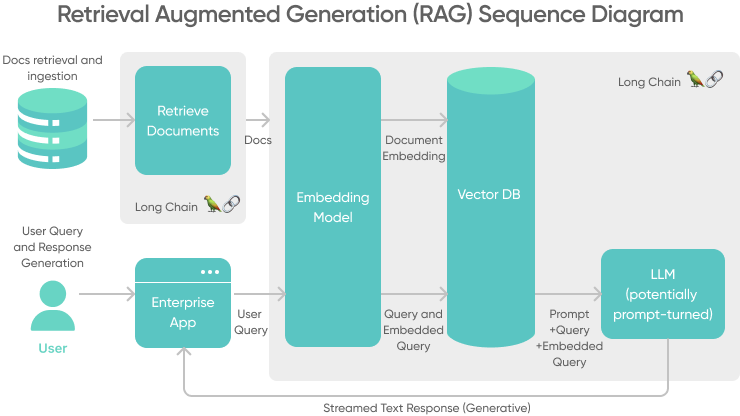
RAG allows you to build AI systems that:
- Access business-specific data: Pull from internal wikis, support tickets, product docs, or customer records so every response is grounded in verified information.
- Counter AI hallucinations: By retrieving relevant context before generation, we dramatically reduce fabricated answers.
- Enhance reliability and transparency: Responses can include source citations, giving users confidence and making debugging straightforward.
In every RAG project I’ve shipped, this pattern has been the difference between a demo and a production system users actually trust.
Load large data sets without atomic transactions
When ingesting massive datasets for AI training, embeddings, or inference pipelines, a single huge transaction can bring your database to its knees. I’ve learned this the hard way in early projects.
While bulk_create with batch_size helps, it still wraps everything in one transaction. The more robust pattern I now use is splitting work across multiple transactions by disabling atomicity in the migration and manually managing commits:
from django.db import transaction, migrations
def import_people_records(apps, schema_editor):
Person = apps.get_model("people", "Person")
transaction.set_autocommit(False)
for batch in read_csv_file("people.csv", BATCH_SIZE):
Person.objects.bulk_create(
[
Person(
name=name,
email=email,
)
for name, email in batch
],
batch_size=BATCH_SIZE,
)
transaction.commit()
class Migration(migrations.Migration):
atomic = FalsePRO TIP: This approach does have a drawback. If an issue occurs during the migration (e.g., loss of database connection), only a portion of the records may be saved, potentially leading to partial data imports.
Despite this, the benefits of avoiding a single large transaction often outweigh this risk, especially when dealing with very large datasets.
Use Celery async tasks for heavy data manipulation
AI workloads (embedding generation, batch inference, data enrichment) are almost always CPU- or I/O-intensive. Blocking the main Django thread is never an option.
Celery has been my go-to for years. It keeps the web app responsive while offloading heavy lifting to background workers.
Here’s an example of a Celery task I use regularly for bulk data operations:
from celery import shared_task
from django.http import HttpResponse
from myapp.models import MyModel
@shared_task
def save_data_to_model(data):
instances = [MyModel(field1=item['field1'], field2=item['field2']) for item in data]
MyModel.objects.bulk_create(instances)
def some_view(request):
data = [{'field1': 1, 'field2': 'a'},{'field1': 2, 'field2': 'b'}]
save_data_to_model.delay(data)
return HttpResponse("Data is being processed!")Celery also powers periodic tasks, third-party integrations, and any long-running AI process. For full setup details, check Celery’s Django documentation.
Minimize database queries with bulk operations
Performance in AI applications often lives or dies by how efficiently you talk to the database. Bulk operations have become a non-negotiable part of my toolkit.
Common scenarios where I reach for them include:
- Data ingestion: Importing large datasets or embeddings in batches instead of row-by-row.
- Batch inference results storage: Saving thousands of model predictions after a single inference run.
- Model training data preparation: Transforming and storing cleaned datasets for fine-tuning pipelines.
- Logging and monitoring: High-volume AI logs and metrics that would otherwise overwhelm the DB.
- Recommendation system updates: Bulk updates for re-ranking or refreshing recommendation caches.
Mastering Django’s bulk_create, bulk_update, and get_or_create patterns has consistently delivered order-of-magnitude speed improvements in the AI systems I build.
AI software development with SoftKraft
If you're looking to build a custom AI solution, our team at SoftKraft specializes in end-to-end AI development. As Python and Django experts with deep LLM experience, we'll help craft your AI strategy, select optimal tech (Django, FastAPI, vector DBs, orchestration frameworks), integrate seamlessly with your stack, and deliver a polished, production-grade AI web application.

Conclusion
Drawing from real-world projects developing AI systems at scale, incorporating these best practices into your Django workflow will significantly boost your application's performance, security, and maintainability. By smartly leveraging Django's strengths, modern AI frameworks, efficient data handling, and thoughtful LLM integration patterns like prompt engineering and RAG, you can create powerful, reliable AI solutions that deliver real business value. Stay hands-on with these techniques, iterate based on production insights, and your AI projects will not only innovate but also stand the test of real-world usage.


