



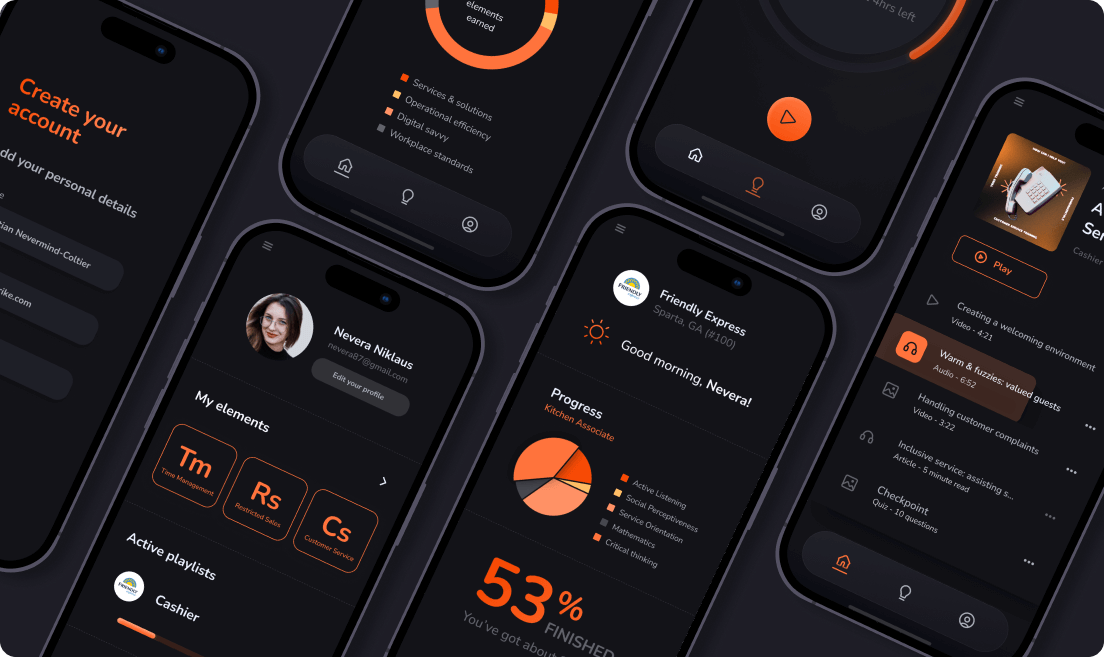
Workforce Training SaaS Platform MVP Development
Platform architecture design, React Native mobile apps, Python backend web app development, testing, and QA of a learning experience MVP

Accelerate your development with our Python developers bringing an average of 9 years of experience to your project. We're so confident in our talent that we offer a free 2-week trial. Contact us and onboard top talent in 10 days or less!
Leverage our Python application development company expertise in web development services, data science, machine learning, and analytics solutions.
Planning product roadmap and estimating the budget for Python projects and infrastructure. Transform business ideas into an actionable plan.
We help startups and SMEs unlock the full potential of data and machine learning algorithms. Leverage our Data Engineering services to build scalable data solutions.
Python web development services will help you create a complete web platform faster, from design and technical decisions to hiring dedicated Python developers.







With predominantly senior Python developers — on average 9+ years of experience — we undertake challenging projects and guide you in creating maintainable software solutions.
Seamlessly scale your engineering team based on project demands with our flexible model, accessing senior Python developers to maintain your project’s momentum.
Turn data into valuable business insights faster. Leverage our expertise at every stage: data collection, cleaning, processing, ML & AI model training, and data visualization.
Engage with our seasoned Python developers through a complimentary 2-week trial, providing a no-risk opportunity to assess their fit for your project.
By implementing ISO 27001 and other certifications, we ensure that our software development services are secure, reliable, and compliant with the highest industry standards.





You can trust that your data is safe and secure with our ISO 27001 certification and best practices in security and data protection.
You get piece-of-mind with our QA processes that adhere to the highest standards for delivering enterprise-grade software products.
You can count on us to quickly adjust to changes in your project needs and provide engineering talent with the required skills.
We partner with entrepreneurs, business and technology leaders to bring their innovative software-driven products, processes, and business ventures to life.








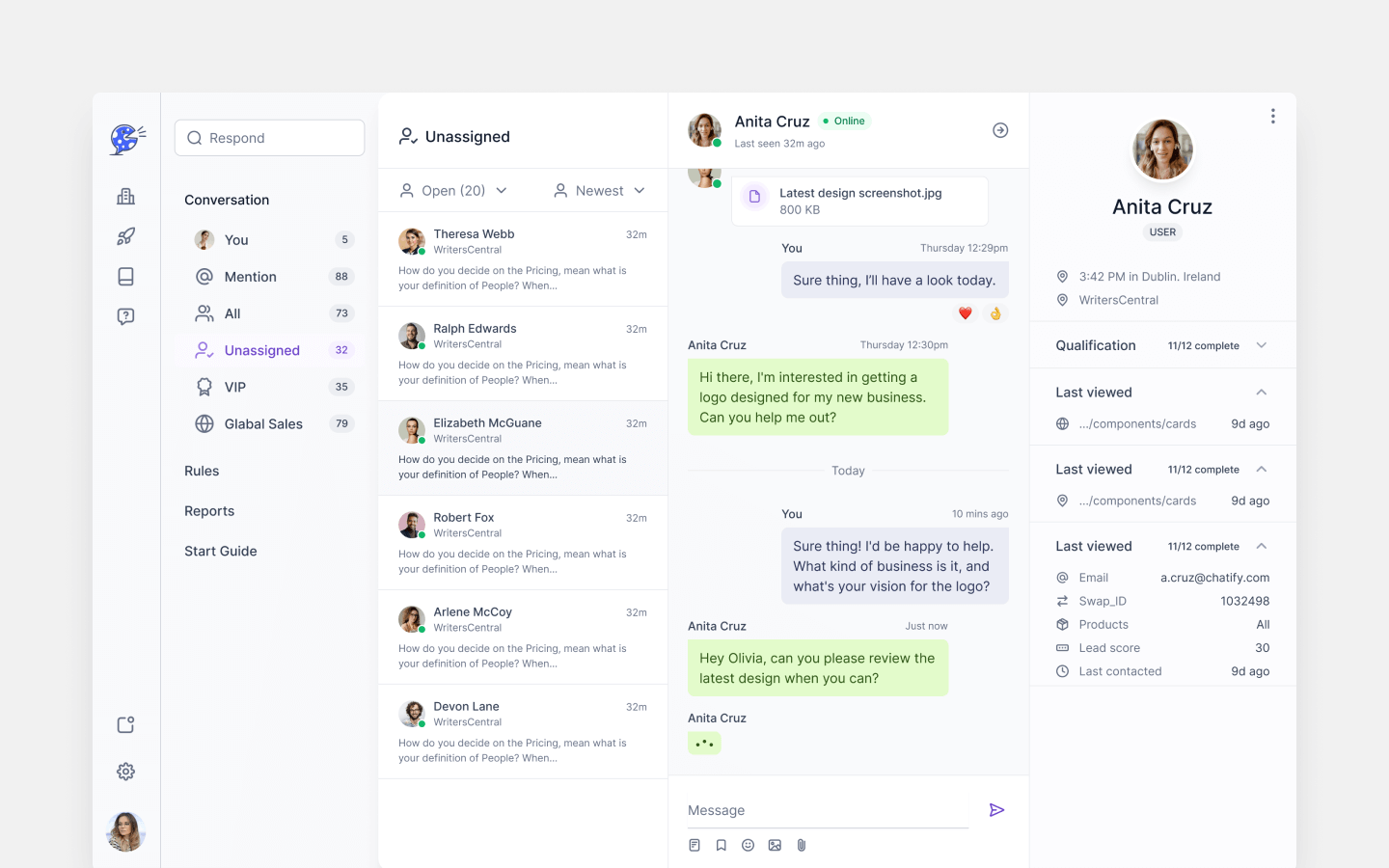
Transform your ideas into software solutions faster with an experienced team of engineers, designers, and product leaders who understand the need for bottom line results.

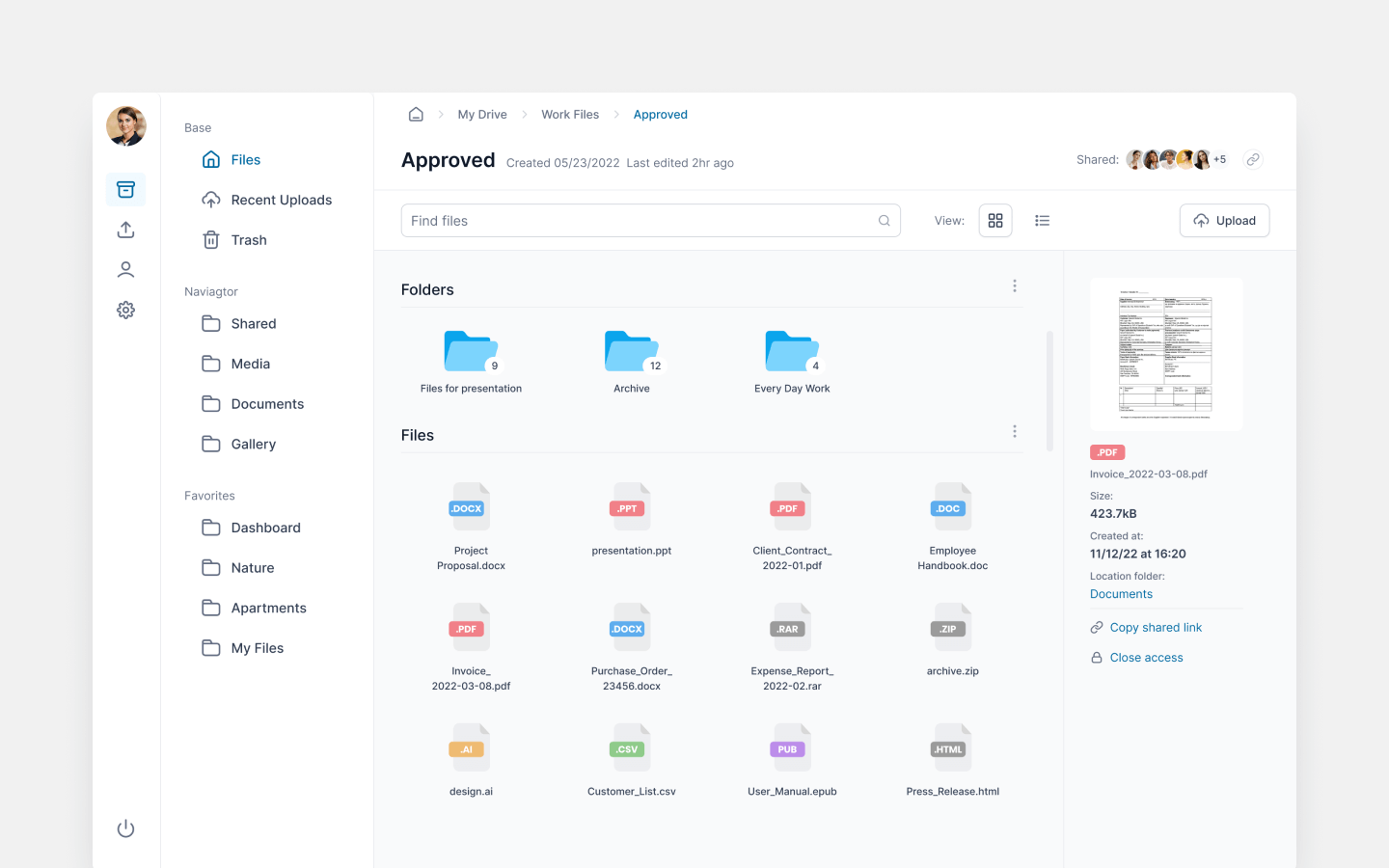
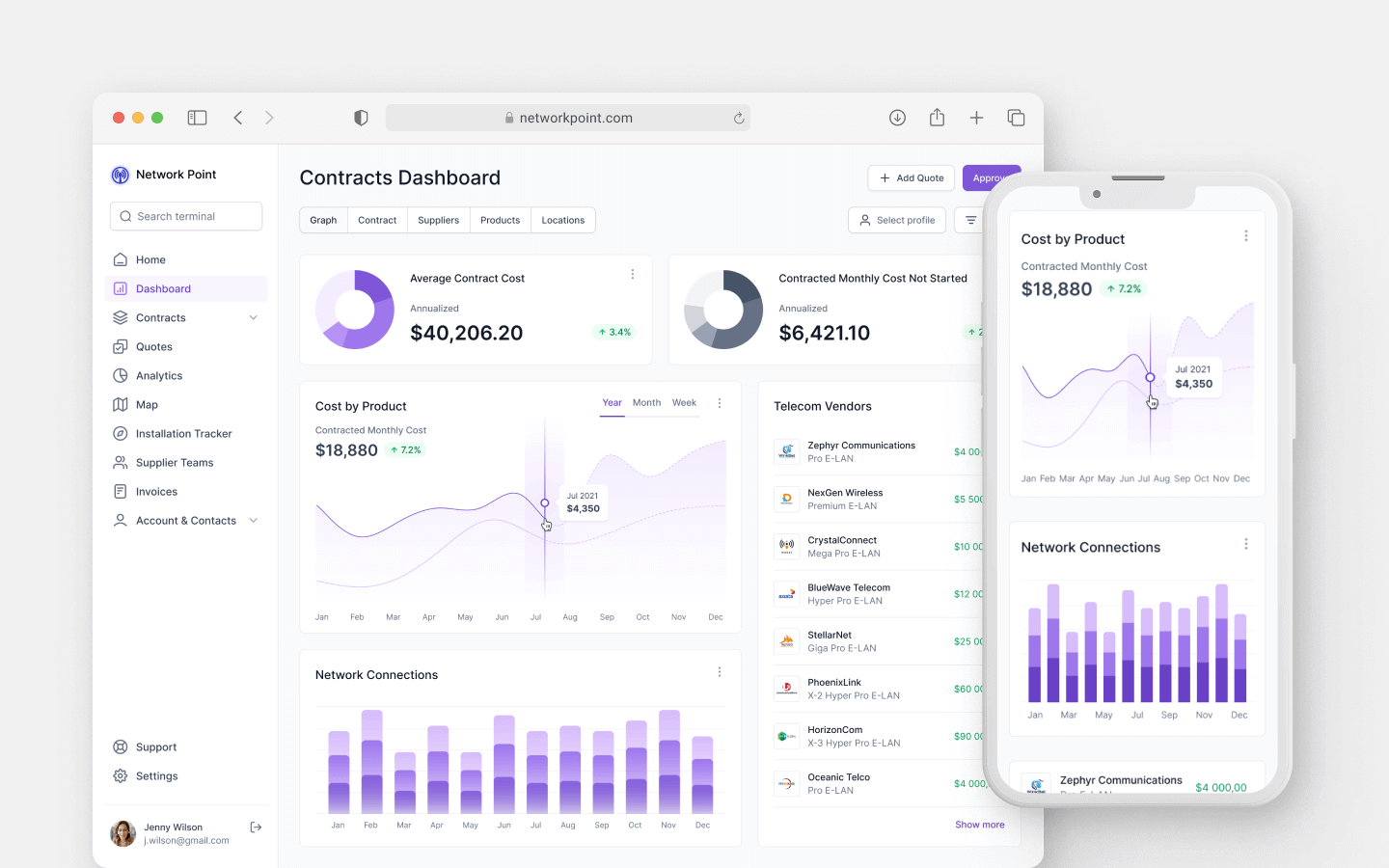
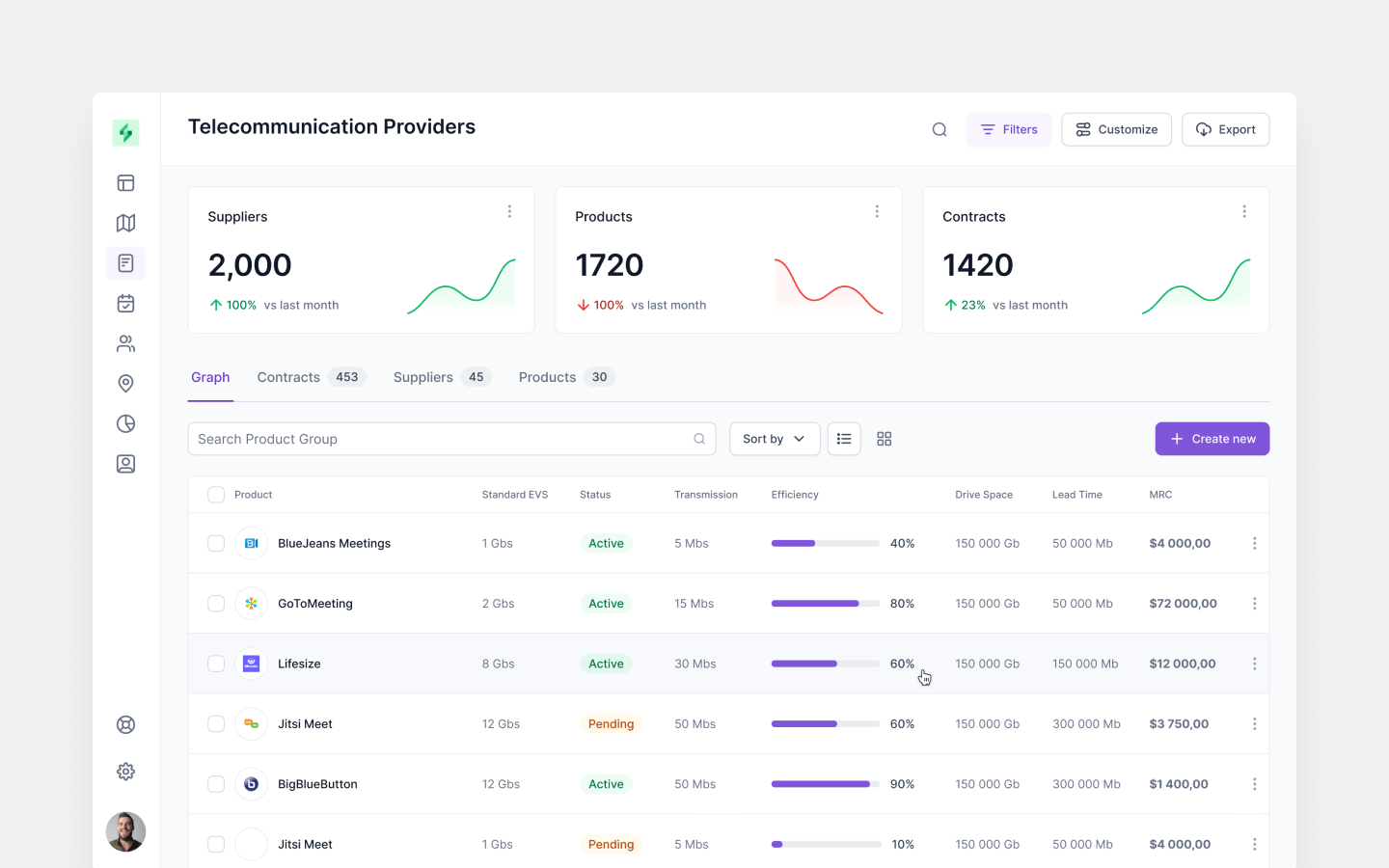
Platform architecture design, React Native mobile apps, Python backend web app development, testing, and QA of a learning experience MVP
Building a scalable, autonomous data engine to index 32,000+ suppliers for a Series Seed startup using Agentic AI
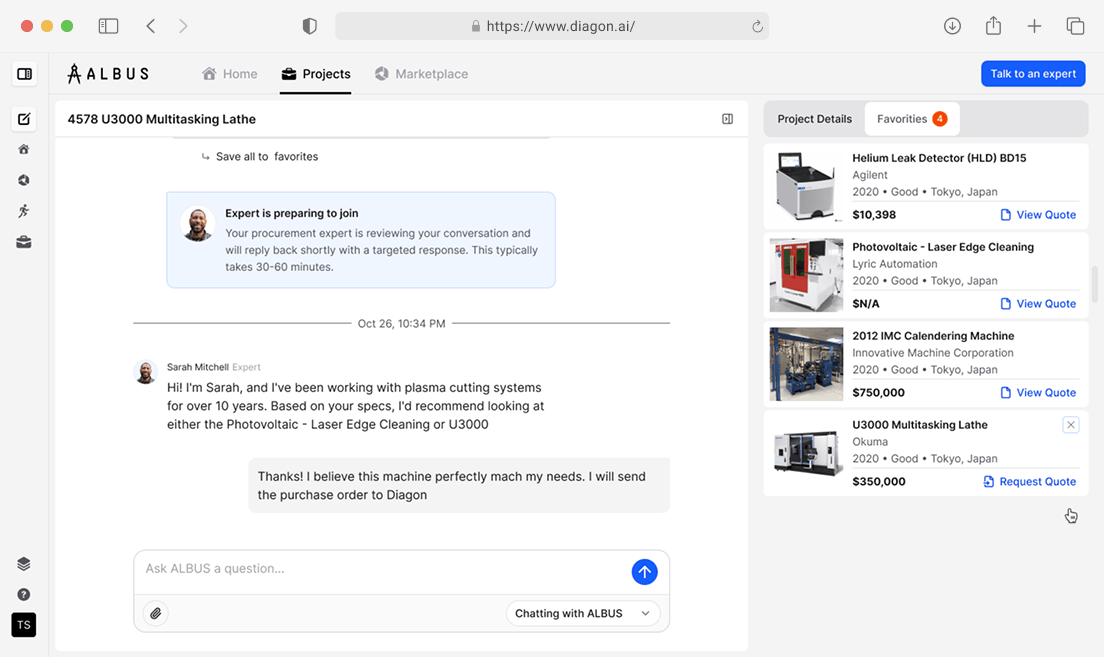
K-12 attendance tracking platform Python development, code refactoring, ongoing support, and monitoring
At SoftKraft we deliver Full-Cycle Software Product Development and we apply Agile Outsourcing techniques, with its emphasis on collaboration. Scope, budget, and timeline are at the heart of project management. We highly recommended starting Python development services with:
1. Approximate estimations based on your goals You will obtain an initial figure that will represent the total estimated cost for the project. This estimation is built on information from the sponsor regarding the expectations and requirements for the product. Here we have to include target users, purpose, and what issue or problem it is intended to solve.
2. Product discovery workshop This event should mark the start of every project request. In this event, you have to gather the whole development team, including scrum masters and project owners, and review the business idea and the details of the future product. By doing this, the team can better identify the required work and budget.
The agile approach makes budget management is a shared responsibility. The Product Owner manages the backlog, the sponsor agrees on the budget, and the team delivers the backlog and spends or manages the sprint budget within agreed constraints.
The final step consists of planning a timeline of the stages you will go throughout the project. You have to break down the tasks that must be completed and connect them to your budget and dedicated team to obtain an initial estimate of the project timeline.
Learn more: Agile Outsourcing — 12 Principles To Guarantee Project Success
Python is a popular programming language that offers enhanced process control capabilities. The diverse application of the Python language is a result of the combination of features that give this language an edge over others:
The beauty of Python, besides its simplicity, lies in the highly established rules the language is built on known as “The Zen of Python”, which can be summarized with this quote:
In reality, programming languages are how programmers express and communicate ideas - and the audience for those ideas is other programmers, not computers - Guido van Rossum, author of the Python programming language.
No other languages on the technology market give so much cost-efficient competitive advantage in software development and automating repetitive tasks. Python allows cross-platform development, web apps development, statistical analysis, data manipulation, machine learning, artificial intelligence, to name a few development solutions.
Building usable web applications in a weekend is the dream of startups and many business leaders. Django framework, which was built explicitly for rapid prototype development, is the closes realization of this idea as you can get. Django is a web application framework that takes care of many of the standard functionalities to build secure and maintainable Python web development. The Django community is exceptionally strong with documentation and long-time support packages of all kinds, like:
But there is a danger. If you cut the wrong corners, you can be stuck with your “prototype development mistakes” for years to come. That’s why for some projects a more minimalistic approach to python web application development Flask or FastAPI python frameworks can be used. Both are suitable for microservices architecture. FastAPI has asynchronous functions and automated generated documents which is very detailed and complete than the Flask framework.
FastAPI is built on Python 3.6+ standard type hints and JSON Schema (used for validating JSON data structure), OAuth 2.0, and OpenAPI (which is a publicly available application programming interface). All of that makes Fast API validate web applications data types even in deeply nested JSON requests. As FastAPI is based on the ASGI standard, it's very easy to integrate any GraphQL library also compatible with ASGI.
FastAPI provides the much-needed upper hand when it comes to speed and asynchronous calling in web development, especially combined with and message queues like Kafka, or Redis. Allows you to break up your web applications into smaller chunks that communicate with each other. This can make it simpler to scale the Python web application development.
The first step to becoming a Python expert is to build a system around your growth as a Python developer is to make an objective analysis of your current skills.
Find the gaps between expert Python programming and your skills. The better the analysis phase, the better your understanding of what are the exact Python programming gaps you need to cover and the more effective the time you will invest later on.
The next step is to build a strategy to get you to the expert level. Expert Python developers have a common understanding of programming concepts way beyond technologies and frameworks. For python web development, a perfect place to fully understand Python development is API Design and understanding the full software cycle (Continuous Integration).
Why? If you are only able to contribute at the Python code level, your ability to help your development team to deliver is limited. Understanding what the frontend developers are trying to achieve, sessions management, state management, and API requests will make you understand how the web really works. At the same time, understanding how backend development Python code gets built, packaged, shipped, and deployed is essential.
Learn more about algorithmic thinking and data structures. Just like professional football players train their muscle memory so that they don’t have to think about it during matches. They, do it on autopilot - without even thinking about it. The same applies to Python programming. Best Python programmers have a structured process when approaching coding problems that they build with a focus on patterns instead of implementation details. And the applying recursion to the learning process of it.

![Top 10 Python Development Companies in Poland 2025 [Verified]](/uploads/blog/python-development-companies-poland/python-development-companies-poland.png)



