
By the end of 2024 it is estimated that 75% of enterprises will shift from piloting to operationalizing AI, driving a 500% increase in streaming data and analytics infrastructures. This will make automating data pipelines even more essential.
In order to fully leverage the potential of your data universe, you must acquire complete control and visibility over all of your data's sources and destinations.
At SoftKraft we help business and technology leaders from start-ups and SMEs to build end-to-end data automation with data engineering consulting. Our data engineers and data scientists can become an integral part of your team and immerse themselves in your project.
In this article, you will learn more about data pipeline use cases, types, and best practices, as well as our data pipeline automation services.
What is a data pipeline?
A data pipeline is a collection of steps necessary to transform data from one system into something useful in another. The steps may include data ingesting, transformation, processing, publication, and movement.
Automating data pipelines can be as straightforward as streamlining moving data from point A to point B or as complex as aggregating data from multiple sources, transforming it, and storing it in multiple destinations. A data pipeline is a byproduct of the integration and engineering of data processes.
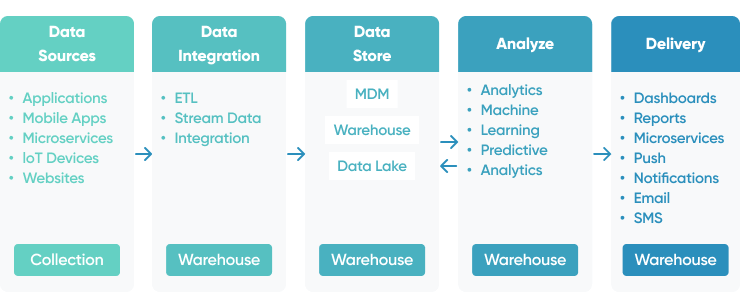
Data pipeline architectures
To meet your specific data lifecycle needs, different types of data pipeline architectures are likely to be required:
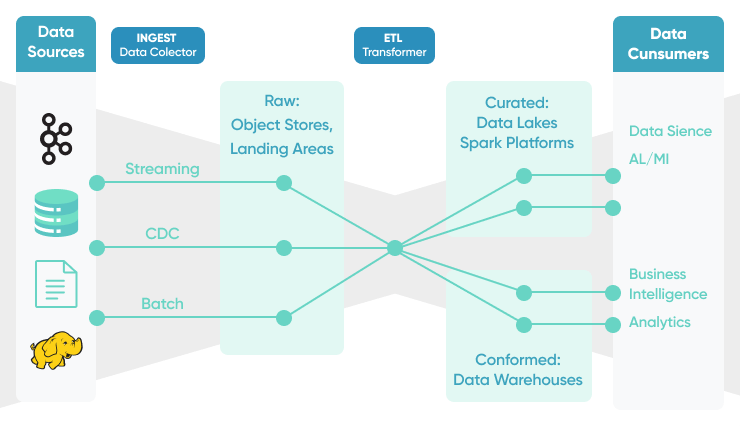
Batch Data Pipeline
Batch data pipeline moves large amounts of data at a specific time, in response to a specific behavior, or when a predefined threshold is reached. It is frequently used to process large amounts of data in bulk or for ETL processing.
For example, a batch data integration could be used to deliver data flowing from a CRM system to a data warehouse on a weekly or daily basis for use in a reporting and business intelligence dashboard.
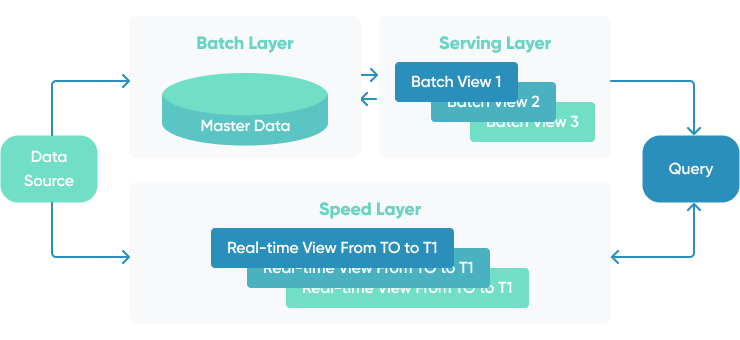
Streaming Data Pipeline
Streaming data pipelines move data from source to destination as it is created. They are used to populate data lakes, as part of the integration of data warehouses, or to publish data to a messaging system or data stream. They are also used in real-time event processing.
For instance, streaming data could be used to feed real-time data to machine learning scoring pipelines such as data analysis for fraud detection. Many data sources can be combined, cleaned, and prepared to be fed into ML scoring algorithms, which generate ratings that assist businesses in making decisions.
ML pipelines must record and return the mandated decisions for further learning via feedback and response pipelines after they have been created. For items with lengthier acquisition cycles, like mortgage applications or life insurance quotations, this procedure may necessitate a latent reaction, such as a website product recommendation.
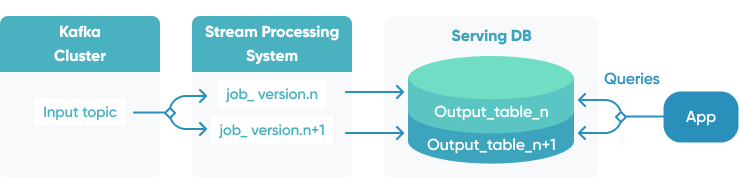
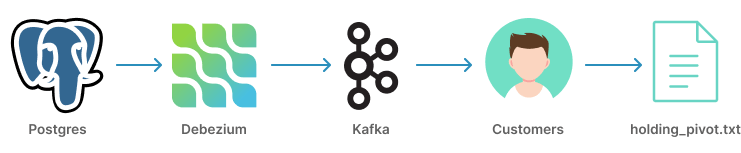
Change Data Capture pipeline
Change Data Capture (CDC) pipelines are used to refresh big data set and maintain consistency across many systems. Rather than transferring the entire database, only data that has changed since the last sync is shared. This is especially important during cloud migration projects where two systems share the same data sets.
Data pipelines challenges
What happens when data flow stops while your business relies on analyzing data? Or data gets lost and never reach its data storage destination? Let’s examine each data pipeline’s challenges one by one.
Always “under construction” data. Building and debugging data pipelines takes time. You must adhere to the schema, set sources and destinations, verify your work, correct problems, and so on until you can eventually go live, at which point the business needs may have changed again. This is why there is such a backlog of work for data engineers.
Data drift (out of order data updates). Each minor, unexpected change to a row or table might result in hours of rework, including updating each stage of the pipeline, debugging, and finally releasing the new data pipeline. Data pipelines frequently have to be taken down for upgrades or corrections. Unexpected changes can result in hidden failures that need months of engineering labor to find and repair.
Built for specific frameworks, processors, and platforms. Data pipelines are customized to work with particular frameworks, processors, and platforms. Changing any of those infrastructure technologies in order to get cost savings or other benefits can require weeks or months of rebuilding and testing pipelines prior to deployment.
Before we discuss how to overcome these obstacles to data pipeline creation, it's necessary to understand how data pipelines work.
Automating data pipelines use cases
A fully automated data pipeline enables your organization to extract data at the source, transform it, and integrate it with data from other sources before sending it to a data warehouse or lake for loading into business applications and analytics platforms.
Data Pipeline Automation streamlines complex change processes such as cloud migration, eliminates the need for manual data pipeline adjustments, and establishes a secure platform for data-driven enterprises.
The three main reasons to implement a fully automated data pipeline are:

Advanced BI and Analytics
According to Gartner, 87% of organizations lack data maturity. Almost all businesses struggle to derive the full value from their data and to derive important insights that might help them increase organizational efficiency, performance, and profitability.
Business intelligence tools and no-code platforms for non-technical business users and democratized data access across the whole organization make organizations data-driven.
Empowered business users can schedule and manage data pipelines, linking and integrating them with cloud-based databases and business applications, and providing the insights necessary to accomplish their goals. By equipping employees with the tools necessary to extract value from data, businesses can build a whole data-driven culture from the ground up.
Better data analytics and business insights
A fully automated data pipeline enables data to flow between systems, removing the need for manual data coding and formatting and enabling transformations to occur on-platform, enabling real-time analytics and granular insight delivery. Integrating data from a variety of sources results in improved business intelligence and customer insights, including the following:
- Increased visibility into the customer journey and experience as a whole
- Enhancements to performance, efficiency, and productivity
- Organizational decision-making that is more timely and effective
Business decision-making capabilities are directly related to the quality of its business intelligence. It begins with data. Today, businesses are gathering more data than ever before and from a variety of sources, but unless they can extract business insight from the data, it becomes a liability rather than an asset.
Establishing a data-driven company culture
By 2023, more than 33% of large organizations will have analysts that specialize in decision intelligence, which includes decision modeling.
Decision intelligence is a term that encompasses a variety of fields, including decision management and decision assistance. It comprises applications in the realm of complex adaptive systems that bridge the gap between numerous established and emerging disciplines.
While digitalization accelerates the collection of data, most businesses are still far from properly leveraging their data and acquiring deeper insights and real-time visibility through advanced analytics. Data is a critical driver of everything from targeted marketing to more efficient operations and increased performance and productivity.
While data collection enables businesses to quantify and measure their assumptions and outcomes, these practices cannot be confined to the executive team in order to foster a data-driven culture throughout the organization.
Schema management
Data schema changes as application and business requirements evolve. Managing multiple versions of data schema at the same time is a challenge. Evolving data schema in a backward-compatible way is a data design skill on its own. Avro-based Confluent Schema Registry is a great example of the schema management solution for Kafka.
Managing data pipelines infrastructure
Managing data pipelines in multiple environments (development, staging, production, etc) can lead to huge costs. Deploying a pipeline into multiple environments can lead to drift between configurations. To ensure that pipelines are properly managed organizations should adopt IAC (Infrastructure As Code) tools like Terraform.
SoftKraft Data Pipeline Automation Services
At SoftKraft help startups and SMEs unlock the full potential of data. Avoid errors, apply best practices, and deploy high-performance Big Data solutions:
Data flow architecture design
Our experts assess the project you’re planning or review your existing deployment. Discover best practices, assess design trade-offs, and flag potential pitfalls to ensure that your team’s projects are well designed and built.
Implementing cloud-based ETL and Cloud Data Warehousing
Implement modern data architectures with cloud data lake and/or data warehouse. Develop data pipelines 90% faster and significantly reduce the amount of time you spend on data quality processes.
Integration with existing data sources and services
Leverage our expertise at every stage of the process: data collection, data processing and the Extract, Transform and Load (ETL) process, data cleaning and structuring, data visualization, and building predictive models on top of data.
Our cloud-first automated data pipelines tool stack
Building a single pipeline for a single purpose is easy. You can utilize a simple tool to create a data pipeline or manually code the steps.
However, how do you scale that process to thousands of data pipelines in support of your organization's growing data demand over months or years?
Cloud-first settings optimize the cloud's benefits, including offloading a large percentage of the maintenance work associated with developing and managing data applications. Because the cloud-hosted approach migrates an on-premises architecture to the cloud, it inherits many of the drawbacks of on-premises systems.
For instance, if a machine learning workload consumes all available resources and requires more. Cloud-first environments automate this process, saving you time and money by managing operations that you would have to create and operate in-house in a cloud-hosted system.
Data applications add value by processing enormous volumes of rapidly changing raw data and delivering actionable insights and embedded analytical tools to clients. There are numerous approaches to data processing, ranging from third-party tools and services to custom coding and deployment.
A modern data platform should offer all of these alternatives, allowing you to choose the one that is most appropriate for your needs:
- Analytical databases: Big Query, Redshift, Synapse
- ETL: Spark, Databricks, DataFlow, DataPrep
- Scalable compute engines: GKE, AKS, EC2, DataProc
- Process orchestration: AirFlow / Cloud Composer, Bat, Azure Data Factory
- Platform deployment & scaling: Terraform, custom tools
- Visualization tools: Power BI, Tableau, Google Data Studio, D3.js
- Programming skills: numpy, pandas, matplotlib, scikit-learn, scipy, spark, Scala, Java, SQL, T-SQL, H-SQL, PL/SQL
Conclusion
Data-centric architectures are key for any organization to achieve its business goals. Data processing pipelines are the foundation of any successful data-centric system. With the rise of cloud computing and managed data services, you can bring the power of scalable data architectures to your organization.
While navigating through the myriad of managed AWS or GCP services can be challenging, our experts can help you to make the right decisions. Tell us your technology requirements and describe your project using our contact form.





