![AWS Security Incident Response Plan [Practical Guide]](/.netlify/images?url=_astro%2Faws-security-incident-response-plan.CEU6rs8J.png&w=740&h=416&dpl=6a2dc680a466470009259c33)
AWS prioritizes cybersecurity for its customers. As a customer, you can leverage the platform’s network architecture and data centers to meet your organization’s needs. AWS employs a shared responsibility model - what this means is that you also possess oversight over your security control.
Moreover, you can make use of different tools and functionalities to achieve your security objectives and establish security baselines for your cloud applications. Anytime there is a deviation from this baseline such as misconfiguration, you can always respond and investigate.
In this guide, we explore the incident domains that require your responsibility, the objectives of your AWS incidence response, and how to prepare for an incident.
Cloud Security Incident Domains
Security incident can occur in the following domains:
Service Domain
Incidents occurring in this domain impact your AWS account, resource metadata, IAM permissions, billing, and other areas. A service domain incident is the one you respond to leveraging AWS API mechanisms exclusively, or an event with root causes related to your resource permission or configurations, and with traces of service-oriented logging.
Infrastructure Domain
Incidents in this domain incorporate activities associated with data or networks like the traffic passing through your Amazon EC2 instances in the VPC environment, data, and processes on your Amazon EC2. It also includes events in other locations such as containers and future services. Your response to events in this domain most times includes retrieval, restoration, as well as generation of data associated with the incidents for forensic analysis. You can also interact with the instances operating system or employ AWS API mechanisms.
Application Domain
Incidents in this domain occur in the software you deployed to infrastructure or service or in your application code. You need to prioritize this domain in your cloud threat detection and incident response runbooks. You can leverage cloud tools such as automated forensics, recovery as well as deployment to manage incidents in this domain. You also need to factor in threat actors who may act against your data, resource, or account.
Shared Responsibility
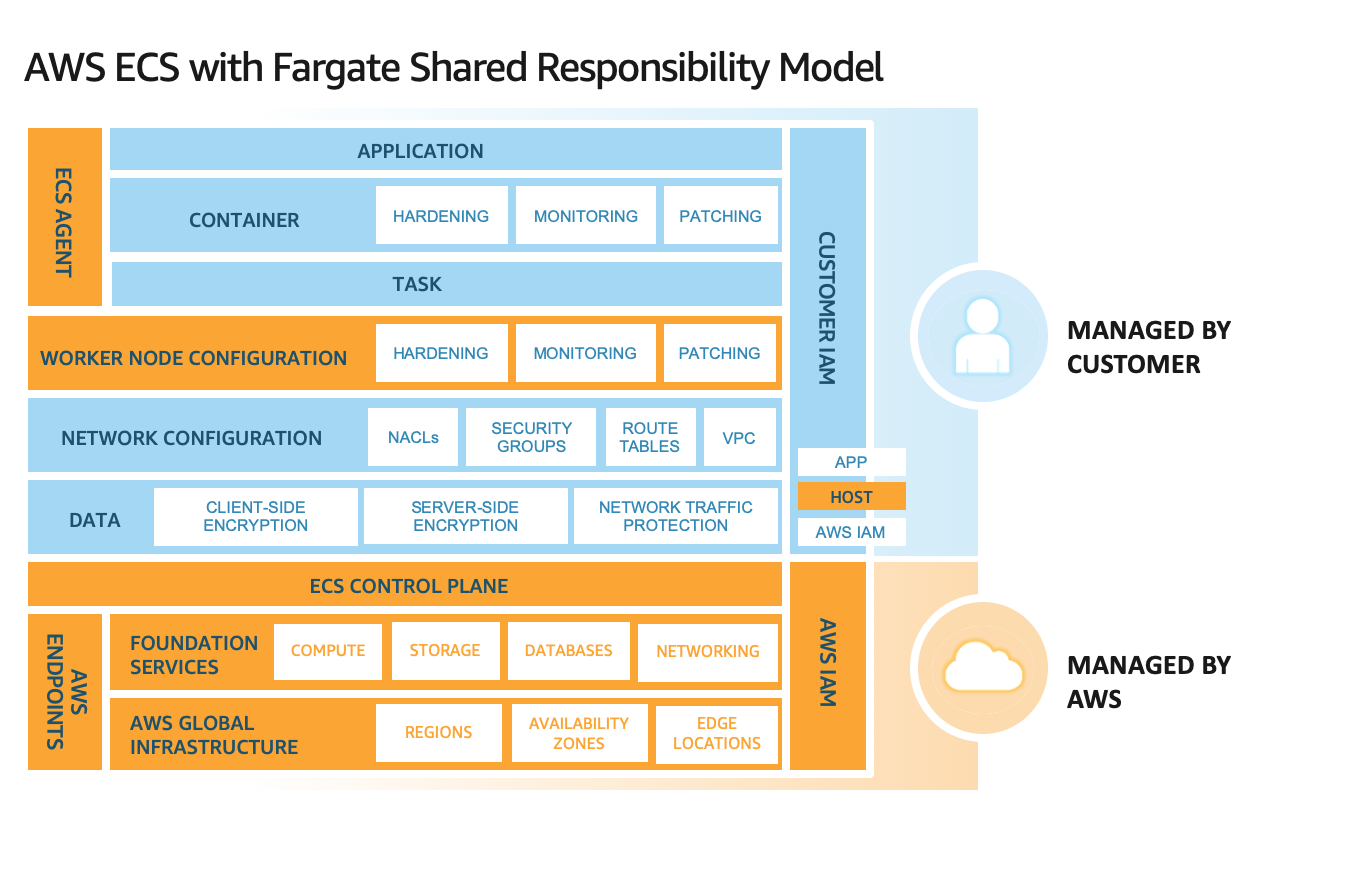
Shared Responsibility means both you and AWS take responsibility for security and compliance. This model relieves you of some operational difficulties as AWS runs, manages, and coordinates the components from the host OS and virtualization layer to the physical security of the facilities that house the operation. It is your responsibility to manage the guest OS. For instance (running updates and installing security patches). It is your responsibility as a customer to also manage application software and the security controls provided by AWS like network access control lists, security groups, and the identity and access management (IAM) systems. The infographic below depicts how the shared responsibility model works in relation to infrastructure services like the Amazon EC2. The responsibilities are shared between AWS who manages the cloud security and the customer who manages the security in the cloud.
Aside from the responsibility you shared with AWS, there may also be other partners or entities that manage some aspects of your cloud technology in your responsibility model. It is important to establish a relevant incident response and forensics runbook that align with your operating model. The better your organization masters the tools you need to purchase or create, the better prepared you will be in meeting the requirements of your governance risk and compliance model.
Now let’s examine the objectives of managing incident response in the cloud.
Goals of Incident Response In the Cloud
The NIST SP 800-61 Computer Security Incident Handling Guide defines the general procedures and strategies for responding to incidents. While the stipulated guidelines in this document are valid, specific design objectives are to respond to incidents within a cloud environment.
Establish response objectives
Collaborate with your stakeholders, C-suites executives, and legal counsel in defining your goals on incidence response. Some common objectives incorporate:
- Containment and mitigation of issues
- Recovery of affected assets
- Preservation of data for forensic investigation and analysis
- Attribution
Respond Using the Cloud
Implement your response strategies where the data and incidents occurred.
Automate Where Possible
As issues and events reoccur, design automation mechanisms that triage and respond to repetitive situations. Leverage human response for fresh, unique, and more sensitive events.
Learn and Improve the Process
Fix any identified gaps in your tools, processes, plan, or people. Simulations remain the best approach to discovering gaps and enhancing processes.
According to the NIST documentation, it is always good to reassess architecture for the capability to respond to incidents and detect threats.
Now that the incident response objectives are clear, how can your organization respond to the incident?
Prepare for Incident Response
Define Roles and Responsibilities
You need to bring the skills and mechanisms of incident response to bear when managing new or large-scale incidents. These incidents depend on the written baseline designed and practiced by your team over time. Since you cannot preempt or codify every possible direction an incident will take, you can use automation for repetitive tasks while humans handle hard tasks.

Also, you need to define and assign responsibilities to those who will be responsible, consulted, reported to, and carried along during an event. You also need to establish third parties that must be involved during the incident response.
Define Response Mechanisms
Your governance, risk, and compliance model should inform your response mechanisms. Usually, you need to design this model before you respond to an incident. Peradventure you have not started, consider it as a prerequisite for building a formidable incident response mechanism.
As you factor in your cloud strategy in collaboration with your team, assess what you have and your requirements. Figure out the relevant people and stakeholders and establish the access to implement response.
While the cloud can offer you optimized visibility via service APIs, your GRC model reveals how to leverage this provision in your response. You can view the technological processes in the prepare technology section of AWS documentation.
Incident Response Process Checklist
Once you have provisioned and trialed relevant access, your IR team needs to define and prepare the processes required for investigation and remediation. This phase demands concerted effort as you need to design the relevant response to security incidents within the cloud environments. Ligase with your team and partners to establish tasks to make these processes work. We also recommend:
Sharing Amazon Cloud Watch Logs
Logs recorded in the Amazon CloudWatch Logs like the Amazon VPC flow logs can be paired with your centralized security account via a CloudWatch Logs Subscription. For instance, you can read the log event data through a centralized Amazon Kinesis stream to implement custom processing and analysis. You need custom analysis to source logging data from several accounts. You can read more on how to configure this early. Check Cross-Account Log Data Sharing with Subscriptions for more information.
Launch Forensic Workstations
Some incident response tasks you need to perform might include the analysis
- disk images
- file systems
- RAM dumps and other artifacts impacted by the event.
Several AWS customers construct a special forensic workstation they can deploy to mount duplicates of any impacted data volumes called the EBS snapshots. If you want to adopt this approach, here are the steps to follow.
- Select a base Amazon Machine Image(AMI) like Microsoft Windows or Linux to be utilized as a forensic workstation.
- Launch an Amazon EC2 instance from the base AMI
- Harden the OS, eliminate irrelevant software packages and configure the auditing and logging procedures.
- Install open source or private toolkits you prefer, as well as vendor packages and software.
- Pause the Amazon EC2 instance and set up a new AMI from the paused instance.
- Establish a weekly or monthly procedure to update and reconstruct the AMI using the latest software patches.
Having provisioned the forensic system using the AMI, your incident response team can employ this provision to establish a fresh AMI to set up a new forensic workstation for investigation.
You can simplify the deployment procedure for launching the AMI as an Amazon EC2 instance. For example, establish a template of the forensic asset resources you require in a text file and post it into your AWS account leveraging AWS CloudFormation.
Once your resources are ready to be deployed from a template, your experienced forensic team can employ the new forensic workstations for individual investigations. This process will isolate cross-contamination from the forensic examinations.
You can also read the Incident Response Plan Template article created for startups to discuss how to design incident response plans and practice runbooks. While developing an incident response plan for your cloud infrastructures can be tedious, we believe the effort is worth it.





