
Global data is increasing rapidly. From 2024 to 2025 alone, global data is expected to surge by 23%, reaching an astonishing 181 zettabytes. Companies are feeling the pressure to manage their ever-expanding data repositories, whether to derive business insights or power next gen AI solutions.
Data pipelines are crucial for efficiently managing and processing this data deluge. In this article, we'll zero in on Python data pipelines, offering 7 expert tips to ensure your systems can handle the explosive growth of internal business data and maintain optimal performance in an era where data growth rates are unprecedented.
What are the basic steps of a python data pipeline?
A data pipeline is a series of processes and tools designed to automate the collection, transformation, and delivery of data from various sources to a destination, such as a database, data warehouse, or data lake. Businesses rely on data pipelines to transform raw data into actionable insights.
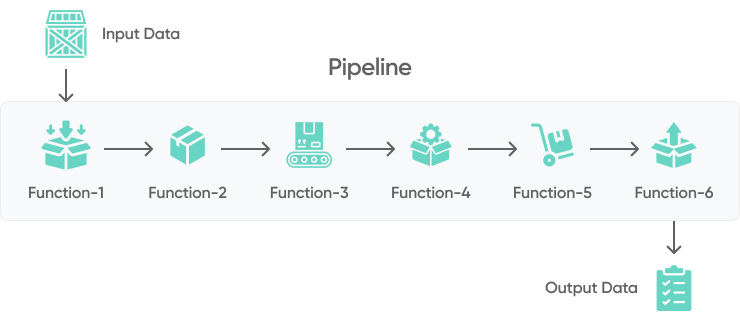
Every data pipeline will have its own set of functions or "steps" in the process depending on its intended function, relevant data sources, and intended data pipeline architecture. But, let's look at the steps in typical Python data pipeline:
- Collect input data: This involves fetching data from various sources using Python libraries such as requests for APIs or pandas for reading files and databases. Efficient data collection ensures that you have all necessary data for subsequent processing.
- Clean up & validate the data: Raw data often contains errors, missing values, or inconsistencies. Cleaning and validating the data involves removing or correcting these issues to ensure data quality. Techniques such as filtering, deduplication, and validation rules are applied to prepare the data for accurate analysis.
- Convert/transform the data: Data transformation is the process of converting data into a desired format or structure. This can involve normalizing data, aggregating values, or enriching the data with additional information. Python libraries like pandas and numpy are commonly used for these transformations.
- Store the data: After transformation, the data needs to be stored in a suitable format and location for easy access and analysis. This could be a relational database, a NoSQL database, or even a data warehouse. The choice of storage depends on the volume, velocity, and variety of data, as well as the specific use cases.
- Analysis and visualization: The final step involves analyzing and visualizing the processed data to extract insights and inform decision-making. Python offers powerful libraries such as matplotlib, seaborn, and plotly for creating visualizations, while pandas and scipy are used for statistical analysis. This step helps in making data-driven decisions by presenting the data in an understandable format.
PRO TIP: Many of the steps in this process can be automated. You can read more about data automation in our articles:
Top technologies to build python data pipelines
Building efficient and scalable data pipelines is crucial for any data-driven organization. In the Python ecosystem, a variety of frameworks and libraries are available to streamline data pipeline creation. Let's explore the top technologies in some of the key pipeline components:
Frameworks
Frameworks are crucial for data orchestration and scheduling, providing tools to manage and automate complex workflows.
- Apache Airflow: Apache Airflow is an open-source tool for creating, scheduling, and monitoring workflows. It uses Directed Acyclic Graphs (DAGs) to manage complex workflows and supports extensive integrations.
- Luigi: Luigi, developed by Spotify, is a Python module for creating data pipelines. It handles dependencies, workflow management, and visualization, suitable for projects with complex dependencies.
- Prefect: Prefect is a workflow orchestration tool designed to simplify data pipeline management. It offers features like automatic retries and flexible configuration, suitable for both simple and complex workflows.
Libraries
Libraries are essential for processing data, offering robust capabilities for numerical computing, data manipulation, parallel processing, and machine learning.
- NumPy: NumPy is a fundamental library for numerical computing in Python. It supports multi-dimensional arrays and mathematical functions, serving as the base for many other data processing libraries.
- Pandas: Pandas is a key library for data manipulation and analysis. It provides data structures like DataFrames and Series for handling structured data and includes various functions for data cleaning and transformation.
- Dask: Dask is a parallel computing library that extends NumPy and Pandas to handle larger-than-memory datasets. It enables parallel and distributed computing, ideal for big data applications.
- Scikit-learn: Scikit-learn is a machine learning library offering tools for data mining and analysis. It includes numerous algorithms and utilities for model training, evaluation, and validation.
7 expert tips to build high-performance python data pipelines
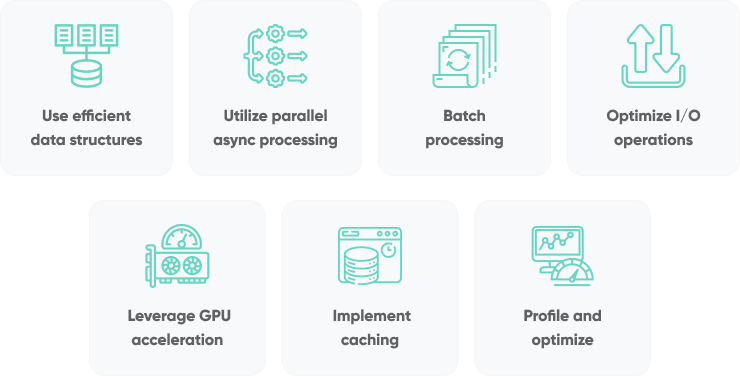
In this section, we'll look at 7 expert tips to help you optimize your data pipelines in Python, ensuring they handle large volumes of data quickly and reliably. Let's get started.
Use efficient data structures
Opting for the most efficient data structures is crucial for building efficient data pipelines. Different tasks require different structures, and choosing the right one can significantly impact the speed and memory usage of your operations. Here are some specific recommendations:
- Use arrays instead of lists for large numerical datasets: Arrays, such as those provided by the array module or numpy arrays, are more efficient than Python lists when handling large amounts of numerical data.
- Choose pandas DataFrames for tabular data: For manipulating and analyzing tabular data, pandas DataFrames offer optimized performance. They are designed to handle large datasets efficiently and come with various built-in functions for data processing.
- Prefer numpy arrays for numerical computations: When performing numerical computations, numpy arrays are highly efficient. They support broadcasting, vectorization, and other advanced features that can significantly speed up your computations compared to using nested lists.
Utilize parallel and asynchronous processing
Leveraging parallel and asynchronous processing can significantly boost the performance of your data pipelines. When you create data pipelines, Python's Global Interpreter Lock (GIL) often poses a bottleneck for CPU-bound tasks. However, using the multiprocessing module can help you overcome this limitation. Here are some specific techniques:
Multiprocessing for CPU-bound tasks
The multiprocessing module allows you to create multiple processes, each running on a separate CPU core. This can be particularly useful for tasks that require significant computational power, such as data transformation, feature extraction, and complex calculations. By parallelizing these tasks, you can reduce processing time and improve overall data pipeline performance.
Asyncio for I/O-bound tasks
For tasks that involve waiting for external resources, such as reading from or writing to a database, making HTTP requests, or performing file I/O, asyncio provides an effective solution. By using asynchronous functions and event loops, asyncio enables your program to handle multiple I/O operations concurrently, thus maximizing throughput and minimizing idle time.
Batch processing
To reduce overhead and enhance the performance of your data pipelines, process data in batches rather than one record at a time. This approach is particularly effective when dealing with large datasets, as it minimizes the frequency of read/write operations and can leverage vectorized operations more effectively. Batch processing allows you to handle multiple records in a single operation, significantly reducing the time spent on I/O operations and increasing throughput.
Batch processing also helps in optimizing memory usage, as it enables you to process smaller, manageable chunks of data rather than loading the entire dataset into memory at once. This can prevent memory overflow issues and ensure your pipeline remains efficient even when handling large datasets.
Optimize I/O operations
While batch processing can be helpful in reducing overhead, there are a number of other I/O optimization techniques you can leverage to improve the speed of your data processing tasks. Let's look at a few examples:
- Use high-performance storage: Storing your data in formats that support quick read/write operations. Formats like Parquet and HDF5 are specifically designed for high-performance data storage. Parquet, for example, is a columnar storage format that allows for efficient data compression and encoding, making it ideal for large datasets. HDF5, on the other hand, is a versatile file format that supports the storage of large amounts of data in a way that facilitates fast access and efficient I/O operations.
- Use buffered I/O: Buffered I/O can significantly speed up read and write operations by reducing the number of system calls. This is achieved by temporarily storing data in a buffer before writing it to disk or before making it available to the application.
- Compression: Use compression algorithms to reduce the size of the data being written to disk. This can decrease the amount of time spent on I/O operations and reduce storage requirements. However, be mindful of the trade-off between compression time and the speed of I/O operations.
- Memory mapping: For very large files, consider using memory-mapped file objects, which allow you to access the data as if it were loaded into memory without actually loading it all at once. This can be especially useful for reading large datasets efficiently.
Leverage GPU acceleration
When building data pipelines, leveraging GPU acceleration can significantly enhance performance, especially for tasks involving large-scale data processing and complex computations. GPUs, originally designed for rendering graphics, are now widely used for their parallel processing capabilities, making them ideal for data-intensive operations.
CuPy is an effective tool for enhancing the performance of Python data pipelines, particularly for large numerical datasets that benefit from GPU acceleration. By implementing the Numpy API and executing operations on NVIDIA GPUs through CUDA, CuPy enables massive parallelism.
Implement advanced caching mechanisms
When your data pipeline involves expensive computations that are repeated, implementing a caching mechanism can save a significant amount of time. Caching allows you to store the results of expensive function calls and reuse them when the same inputs occur again, reducing the need for redundant calculations and speeding up your data processing tasks. Here are some ways to implement advanced caching mechanisms:
- joblib for function caching: joblib is a library designed for parallel computing but also provides powerful caching utilities. It can be used to cache the results of function calls to disk, making it ideal for long-running computations that you don't want to repeat. With joblib, you can specify the cache location and the conditions under which the cache should be used, allowing for flexible and efficient caching.
- functools.lru_cache for in-memory caching: Python's functools.lru_cache is a simple yet effective way to cache results in memory. It uses a least-recently-used (LRU) strategy to discard the least-used entries when the cache reaches its limit, ensuring that the most frequently accessed results remain readily available. This can be particularly useful for smaller, frequently repeated computations where in-memory caching is sufficient.
- Distributed caching: For larger, distributed systems, consider using distributed caching solutions like Redis or Memcached. These tools allow you to store and retrieve cached data across multiple nodes, providing high availability and scalability for your cached results.
Profile and optimize
Regularly profiling your data pipeline helps identify bottlenecks and ensures optimal performance. Python offers profiling tools like cProfile and line_profiler to analyze where your code spends most of its time. Use this information to target specific areas for optimization, such as improving inefficient algorithms, reducing I/O wait times, or optimizing data transformations.
In addition to these profiling tools, consider integrating monitoring and logging mechanisms into your pipeline to provide real-time insights into its performance. Tools like Apache Spark's built-in monitoring or third-party solutions like Prometheus and Grafana can help track metrics such as execution time, resource usage, and error rates.
Data engineering with SoftKraft
At SoftKraft we offer data engineering services to help teams modernize their data strategy and start making the most of their business data. Our python development team will work closely with you to understand your unique business challenges, develop a strategic solution, and build a customized system tailored to your needs. At the end of the day, the only metric that matters to us is project success.
Conclusion
In an era of exponential data growth, optimizing your Python data pipelines is essential for maintaining high performance and reliability. By leveraging advanced techniques such as parallel processing, GPU acceleration, and efficient data structures, you can ensure your pipelines handle large volumes of data efficiently today and long into the future.





